European Science Foundation Second Language Databank (ESFSLD)
| Introduction | References | Corpus Structure | Corpus Information |
| Document Information | Header Information | Metadata Overview |
Last update: 18-Sep-2000
The ESFSLD is a computerized archive of data collected by research groups of the ESF-project in five European countries: France, Germany, Great Britain, The Netherlands and Sweden. The project concentrates on the spontaneous second language acquisition of forty adult immigrant workers living in Western Europe, and their communication with native speakers in the respective host countries.
Feldweg, Helmut. 1992. The European Science Foundation Second Language Databank
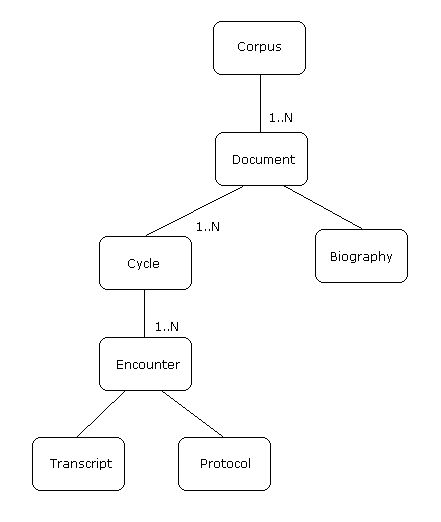
The corpus consists of a directory containing the names of the target languages. The target language directories have subdirectories with names of source languages in which the data files from the subjects are stored. A custom coding convention is used to classify and identify these files.
Document data is distributed over the following three file types:
The ESFSLD headers in the RAW and BIO files are flat structures with attribute-value pairs. No descriptions for attribute-value pairs from the BIO files were available. In addition to the main attribute-value pairs the BIO files there are three sections: fixed characteristics, variable characteristics and a list of encounters. Those sections are not described here.
| Encoded in the filename | ||
| Informant type | There are three types of informants: longitudinal, control and long residents | |
| Source language | **** see transcription **** | |
| Target language | **** see transcription **** | |
| Informant | **** see transcription **** | |
| Cycle number | Cycle to which a particular session belongs | |
| Sequence number | Sequence number of an encounter within a cycle | |
| Activity type | Activity type of the encounter | |
| Transcription (RAW) | Contains information about the raw transcripts of the encounters | |
| Filename | (external) name of the file | |
| Informant | One-letter abbreviation and pseudonym used for informant(s) in the file | |
| Interviewers | One-letter abbreviation and name (pseudonym) used for interviewer(s) in the file | |
| Subject | **** same as informant **** | |
| Source language | Source language of informant (native language) | |
| Target language | Target language of informant (language to be learned) | |
| Date | Date of encounter | |
| Cassette | Label of audio/video cassette used for recording of encounter | |
| Recording | **** same as cassette **** | |
| Episode | Short description of transcribed episode | |
| Comments | Any comments concerning the episode | |
| Keywords | Keywords concerning relevance of transcribed data for specific analysis | |
| Transcribed by | Name of transcriber of the data | |
| Revised by | Name of revisor of the transcription | |
| Checked by | **** same as revised by **** | |
| History | Records of changes applied to the file | |
| Protocol (PRT) | Contains a sort of protocol of an encounter | |
| Socio-biographical (BIO) | Contains socio-biographical information about the informants (subjects) | |
| Group | ? | |
| Subject | ? | |
| Source language | ? | |
| Target language | ? | |
| Date of Birth | ? | |
| Sex | ? | |
| Religion | ? | |
| Fixed Characteristics | ? | |
| Variable Characteristics | ? | |
| Encounters | ? | |