ELAN offers several ways to interact with web services. These web services are tools or applications that run on a web server, accept some resource(s) as input, apply an algorithm and return the result as output. Some of the Recognizers in the Section 1.5.12 tab are available as a web service, in which case audio or video or any other type of sequential data are uploaded to be processed online. The web services available in this menu work with text rather than multimedia content. These tools can automate certain parts of the annotation process, such as tokenizing and part of speech tagging. These web services can be found by clicking . WebLicht is described in the next section, support for TypeCraft is still experimental.
WebLicht (Web-Based Linguistic Chaining Tool, http://weblicht.sfs.uni-tuebingen.de/weblichtwiki/index.php/Main_Page) is a framework developed at Tuebingen University as part of the CLARIN infrastructure. Most of the tools in this framework perform NLP (Natural Language Processing) type of tasks on textual data and most of them are tailored to work with language data in one of the well-described and well-resourced languages.
To make use of the WebLicht service, go to . In the dialog that opens, you can choose to start the Weblicht processing by uploading plain text or to select one or more tiers.
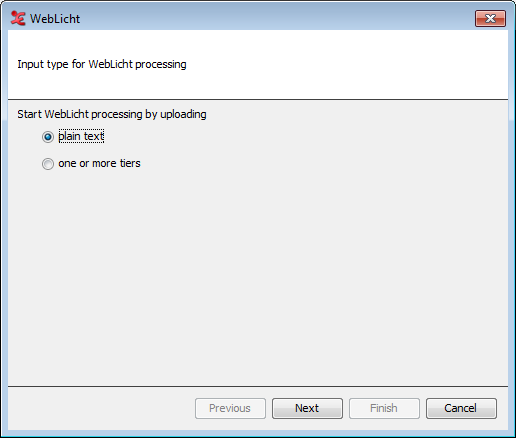
Choosing the plain text option and clicking Next will bring up a dialog in which you can paste or type plain text.
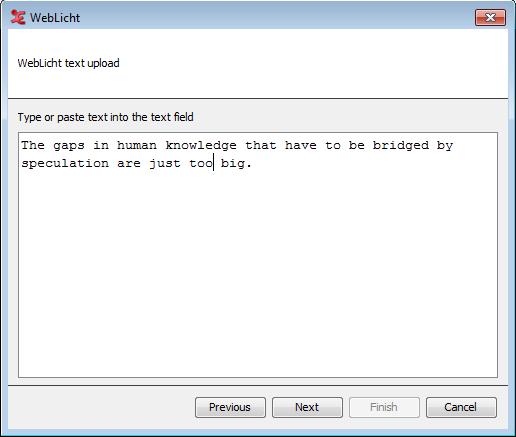
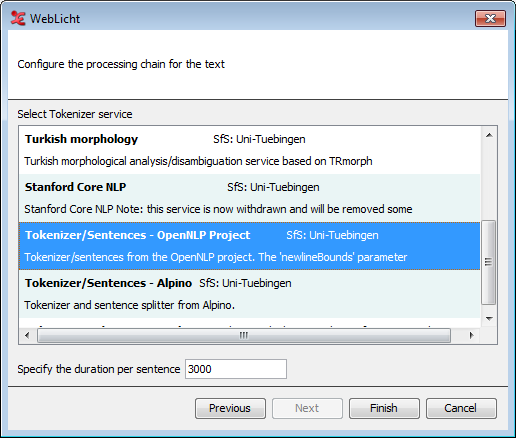
After inserting your text into the field, click Next to configure the processing chain of the text. WebLicht provides several services that detect sentence boundaries and then tokenize these sentences. The tokenize services are listed here and you can select one. In case of successful processing the result will be two tiers, for sentences and tokens. If you want to add Part of Speech and/or Lemma annotations, you can use the tiers produced in this step as the input for such services (part of speech taggers) in a second run. There is an option to specify the duration (in ms) of each sentence. When done, click Next.
It is also possible to choose a tier from the current document that you want to
process with the Weblicht service. In order to do that, choose One or more
tiers in the first dialog. At the moment only one tier at a time can be
selected.
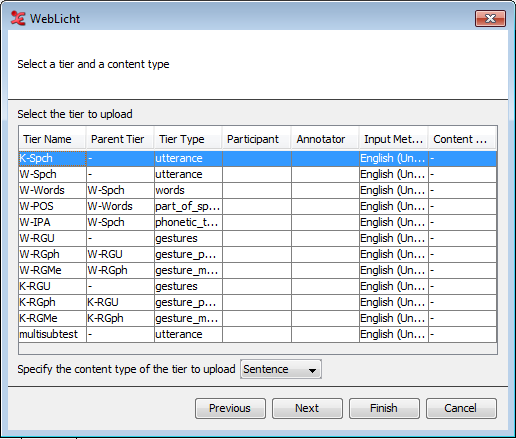
Next, select the tier for processing and specify its content type
(Sentence if the annotations on the selected tier contain sentences
or Word/Token if the annotations contain single words). There are some
limitations on the tiers you can select for each type; Sentence tiers
are expected to be a toplevel tier or a symbolically associated dependent tier thereof,
Token tiers are expected to be on a symbolic subdivision tier. Click
Next to specify a WebLicht web service that you wish to use on
the tier. Different services are available, which can parse text, tag Parts of Speech,
etc.
Each service has a short description that specifies its function. Hovering over a service with the mouse will show a tooltip containing more information of the service. If the service you are looking for is not listed, you can manually specify its URL.
When done, click Finish to start processing. When the processing was successful, you will see a dialog stating the operation is complete. Depending on the service you selected for processing, the tokenized sentence and/or part of speech tags will be added as children of the tier you selected for processing.
