| |
| |
|
Mission and task People Existing Tools Schemas or Format Descriptions Standardization Initiatives Important Dates Links:
|
This document serves to summarize what has to be done in Workpackage
2 of the ECHO project. It first repeats gives an overview about Technology
in ECHO, second what is stated in the technical annex as tasks for WP2
and then gives some interpretations. 1. Technology in ECHOTechnology issues are one of the four main pillars of ECHO.
Technology is dealt with at various layers: (1) It is natural part of
the AGORA discussions, in particular between specialists from the humanities
disciplines and technology; (2) It is part of the content provision
work in so far that the content providers use tools and have to integrate
their resources into a browsable and searchable domain; (3) It is subject
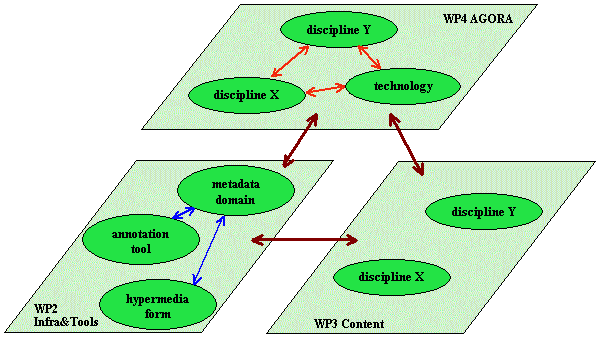
of the Infrastructure and Tools work package. The following diagram
describes the interaction between these ECHO layers. The content provision teams will use the already existing tools,
but also receive new versions created within the ECHO framework. They
will discuss with the developers about the usage of the tools, their
errors and useful extensions. They will use the AGORA to discuss the
requirements and visions of the discipline. The technologists will interact
amongst themselves to meet the goals, interact with the content providers
about the emerging tools and how to use them. They also will use the
AGORA to present the state of the art in technology and their visions
about how technology will develop. Further, they will listen to the
requirements from the disciplines to extract roadmaps for future developments.
The details are described below.
2. Technical Annex 1.
To build a prototypical browsable and searchable knowledge
base that can be easily used online by researchers and the interested
public. It will be based on current metadata standards such as DC and
IMDI and cover language resources from 12 European institutions and the
resources gathered in WP3. 2.
The realization of a hypermedia form to gather information
about non-European cultural heritage. 3.
To develop a multimedia annotation tool which allows people
to work collaboratively on a multimedia resource and to add comments to
it, although being at different locations. The result
must be an integrated demonstrator which will be based on existing Java-based
solutions of the partners and which use open standards such as XML-based
interchange formats. Both - infrastructure and technology - have to be
integrated and to demonstrate the potential of a Common Technological
Framework covering several disciplines. Description of Work First, the requirements
and the existing solutions of the content provision tasks in WP3 will
be determined. In parallel, specifications will be drawn for the web-based
multimedia annotation and commenting tool. Also in parallel the specifications
of the hypermedia form will be worked out. Second, tool adaptation
and development has to be carried out. The existing metadata tools have
to be adapted with high priority to make them available to the teams to
enter metadata. In parallel, the hypermedia form for non-European cultural
heritage will be developed. Its usage in collaborative scenarios is planned
to be realized at the end of the development phase (T15).
Third, the participating
institutions will apply the available tools and create metadata descriptions
and annotations. Fourth, the two
domains infrastructure and annotation/commenting tool will be integrated
such that the tool can be started when browsing within the metadata description
domain and when a useful resource was found by the user. Therefore, the
final demonstrator will give access to the content developed in WP3 to
demonstrate the innovative research capabilities. Deliverables D2.1 Specification
Report covering specifications for the infrastructure and the collaborative
annotation tool
T6 D2.2 Specification Report for the technical realization of the model forms for non-European cultural Heritage T10 D2.3 Prototype of
the hypermedia form for non-European cultural heritage
T10 D2.4 A demonstrator
covering the infrastructure and the collaborative tool in an integrated
way 3. InterpretationFirst, we will discuss the three
objectives separately and then speak about the integration that is mentioned. 3.1 Infrastructure(main actors: U Lund and MPI Nijmegen) The work will be based on the IMDI
metadata (see note 1) which has been worked out in
the European ISLE project (www.mpi.nl/ISLE). A mapping was defined between
the IMDI set and the DC set, i.e. the DC domain is included as a subset
and if data providers in ECHO would prefer to deliver DC records it would
be acceptable although it is not a satisfying solution due to its inherent
limitations. The IMDI set will be further developed also within the INTERA
(Integrated European Language Resource Area) and the DOBES (Documentation
of Endangered Languages; www.mpi.nl/DOBES) projects. It has to be analyzed
in detail what kind of metadata descriptions other ECHO content providers
may require or deliver. Additional adaptation or mapping work may be necessary
to come to one integrated infrastructure. The description of work states
that the existing IMDI metadata tools developed within the ISLE/IMDI project
have to be extended according to the modifications of the IMDI set and
the possible integration requirements. The tools already now guarantee
the possibility of browsing and searching in a metadata domain that is
the knowledge base that is mentioned under objectives. The description of work further states
that the metadata tools have to be adapted with high priority so that
teams can enter metadata and enrich the browsable domain. The goals section
states that the domain should cover language resources from 12 European
institutions and the content work in WP3. Lund and MPI Nijmegen have to
establish a list of institutions providing language resources relevant
for the ECHO initiative. A first workshop about extending
and adapting the IMDI set took place at 14/15. November 2002. Contacts
with the History of Arts specialists are established to map the MIDAS
set with IMDI and to understand how the metadata records can be retrieved
from the HIDA-MIDAS database. First contacts have been established with
other partners in ECHO as well. An overview about the resources to be
delivered revealed that in most cases no explicit schemas are yet available,
i.e. most content providers did not yet think about how to present their
resources with metadata. Given this situation a first demonstrator
of a true ECHO domain until September 03 with a few selected partners
seems to be possible. The actual integration and training work will be
carried out by Lund U (MPI Nijmegen will certainly help when necessary).
Of course, this new ECHO domain will be integrated with the existing and
emerging IMDI domains. As already mentioned an opening with reduced metadata
to the DC and OLAC domain is supported. After September 03 a second phase
of the work will start that could even integrate more resources. To be
able to do this the different requirements must have become more apparent.
|
||||||||||||||||||||||||||||||||||
3.2 Multimedia Tool Development(main actors: MPI Berlin, U Bern, MPI Rom, MPI Nijmegen) Mainly the functionality of two major
existing tools have to be merged within the ECHO framework: U Berns
DIGILIB and MPI Nijmegens ELAN annotation tool. Further, text technology
functionality from Berlin has to be integrated where possible. The above
mentioned two programs are the basis for what is called the development
of a multimedia annotation tool. What has to be created within the
ECHO framework are tools that allow:
We are faced here with a couple of
problems that have to be solved:
Further, the requirements of the
various disciplines in WP3 have to be understood better. It may be that
we have to add some functionality, if it is not too complicated and
does not distort the time plan. The proposed time scale for the work
at this moment is:
|
|||||||||||||||||||||||||||||||||||
Last
update:
January 2, 2003
by A. Verbunt |
|||||||||||||||||||||||||||||||||||