Calculate inter-annotator reliability
In some projects two or more annotators annotate the recordings and the need exists to assess the level of agreement, in order to be able to improve the training of the annotators and in the end the annotation quality. Several algorithms have been implemented and are being applied in research projects but there doesn’t seem to be consensus on what the best approach is for this type of data (time aligned annotations). The option allows to calculate an agreement measure for annotations on multiple tiers in multiple files, providing three different methods based on existing algorithms. Even though multiple tiers can be selected, the comparison is always performed on pairs of tiers. These methods are provided “as is”. Implementation of other algorithms might be added later, if time allows. The three methods are:
calculation of (modified) Cohen’s kappa according to Holle & Rein
calculation of (modified) Fleiss’ kappa
calculation of the ratio of the overlap and the total extent of two annotations
calculation of the degree of organization using Staccato
Using the function requires a few steps to be taken. Some of the steps differ depending on the choices made; other steps are common to all methods. The steps and their availability depending on the choices made are described below.
1. Method selection - selection of the algorithm that will be applied
2. Customization of the selected method (if applicable )
3. Document and tier configuration
4. Select files and matching (not available when current document & manual selection is chosen)
5. Tier selection
6. Execute the calculation and save the output file
The following sections will describe each step of the process in more detail.
Step 1. Method selection
Figure 146. 1. Method selection
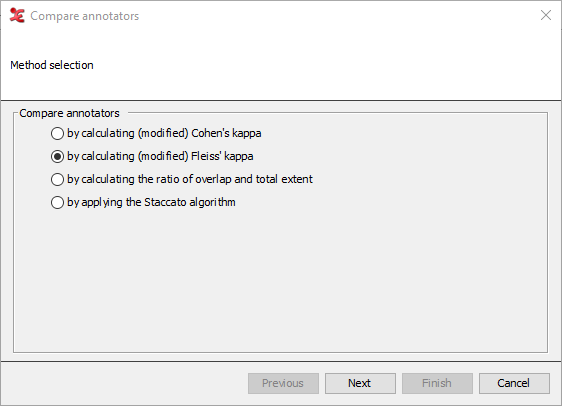 |
The first step in the process allows you to select a method of comparing. Depending on what method is selected, the steps after that will differ. The options to choose from are:
By calculating modified Cohen’s kappa:
This option implements (part of) the Holle & Rein algorithm as described in this publication: Holle, H., & Rein, R. (2014). EasyDIAg: A tool for easy determination of interrater agreement. Behavior Research Methods, August 2014. The manual of EasyDIAg can be consulted for a detailed description and explanation of the algorithm.
By calculating modified Fleiss' kappa:
This option provides a modified implementation of Fleiss' kappa. The modification concerns (as is the case for the modified Cohen's kappa implementation) the matching of annotations to determine the "subjects" or "units" and the introduction of the "Unmatched" or "Void" category for annotations/events that are not identified by all raters. If the raters only have to apply labels to pre-existing segments, the problem of matching annotations does not exist. Fleiss' kappa works for two or more raters (the other options are limited to two raters).
by calculating the ratio of overlap and total extent:
This is a simplified version of the function that used to be under > . It calculates a raw agreement value for the segmentation, it doesn't take into account chance agreement and it doesn't compare annotation values. The current implementation only includes in the output the average agreement value for all annotation pairs of each set of tiers (whereas previously the ratio per annotation pair was listed as well).
by applying the Staccato algorithm:
This will compare the annotations (the segmentations) of 2 annotators using the Staccato algorithm. See this article for more information on the Staccato algorithm: Luecking, A., Ptock, S., & Bergmann, K. (2011). Staccato: Segmentation Agreement Calculator according to Thomann. In E. Efthimiou G. & Kouroupetroglou (Eds.), Proceedings of the 9th International Gesture Workshop: Gestures in Embodied Communication and Human-Computer Interaction (pp. 50-53) .
Once you choose a method, click to continue. Note that when the Kappa or Staccato are chosen, the next step will be 'Customize compare method'. Otherwise the next step is 'Document & tier configuration'.
Step 2. Customize compare method
Figure 147. a. Customize compare method for modified Cohen's kappa
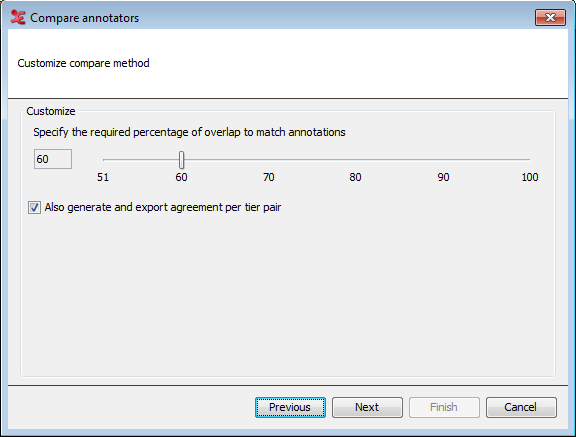 |
When the modified Cohen's kappa method is chosen, this step allows you to specify the minimal required percentage of overlap. This is the amount of overlap as a percentage of the duration of the longest of the two annotations. The higher the percentage, the more the annotations have to overlap to match.
You can choose to generate and export agreement values per pair of tiers, in addition to the overall values. Since this algorithm compares annotation values as well, it is best to select tiers that share the same (controlled) vocabulary. When done, click .
Figure 148. b. Customize compare method for modified Fleiss' kappa
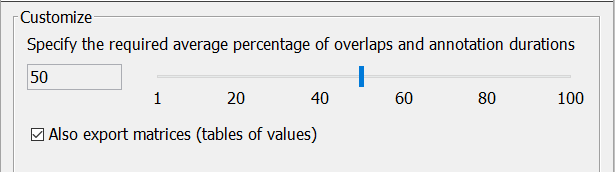 |
The options for Fleiss' kappa are slightly different; the slider here allows to specify a percentage between 1 and 100. Since there can be any number of raters, the annotation matching algorithm tries to create clusters of as many overlapping annotation as possible, taking into account the required average of the percentages of the overlap and each involved annotation's duration. The figures below try to illustrate the problem.
Figure 149. Six raters, two possible clusters of four and six matching annotations, the overlap in light blue
 |
Figure 150. Six raters, four of the possible clusters of matching annotations are marked in blue and green
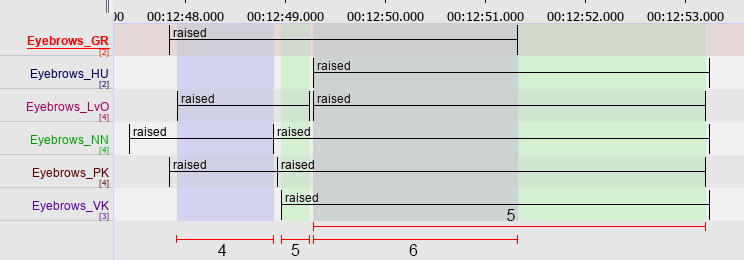 |
The algorithm gives preference to clusters with more annotations, as long as the required average percentage of overlap is met. If not, a cluster with less annotations is selected. Each annotation can only be part of one cluster.
The checkbox allows to not save the tables of values (see the worked example at Wikipedia), but it is recommended to accept the default.
Figure 151. c. Customize compare method for Staccato
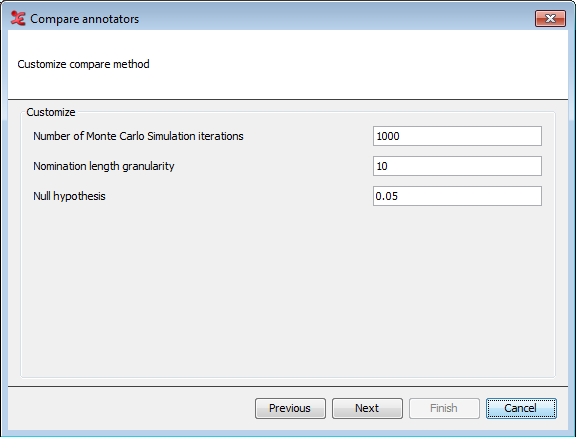 |
When you've selected the Staccato algorithm as the compare method, the settings as shown above will appear. You can customize the settings for the Staccato algorithm here. This algorithm takes chance into account by comparing the segmentation with a series of randomly generated segmentations, the Monte Carlo simulation. The nomination length granularity determines how many memory slots for segments of different length will be used internally. For more in-depth information regarding these settings, please see the reference article mentioned before. When done, click .
Step 3. Document & tier configuration
Figure 152. 3. Document and tier configuration
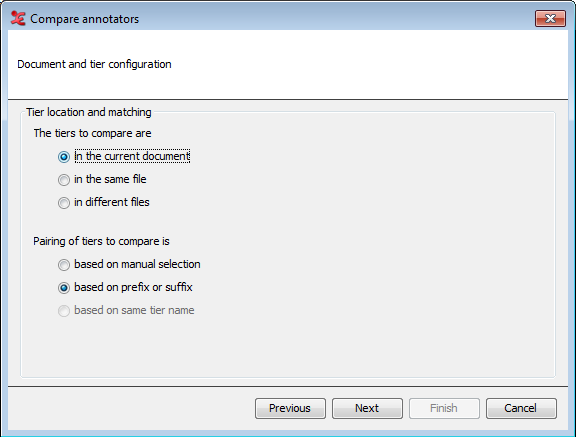 |
The next step is to configure where the tiers that you want to use for comparison are located and how they should be paired. In the upper part of the dialog, you select the location of the tiers:
In the current document (available when you have an .eaf file open, otherwise this option will be greyed out)
In the same file (choose a single file in the next step)
In different files (choose multiple files in the next step)
In the lower part of the dialog, you can select in what way the pairing of tiers to compare is done:
Based on manual selection (select tiers from a list in the next step)
Based on prefix or suffix (customize in the next step)
Based on same tier name (only available when the option 'in different files' is chosen)
When done, click to continue.
Step 4. Select files & matching
Next, you will select which files you want to use for comparison and how to match tiers.
Figure 153. 4. Select files & matching
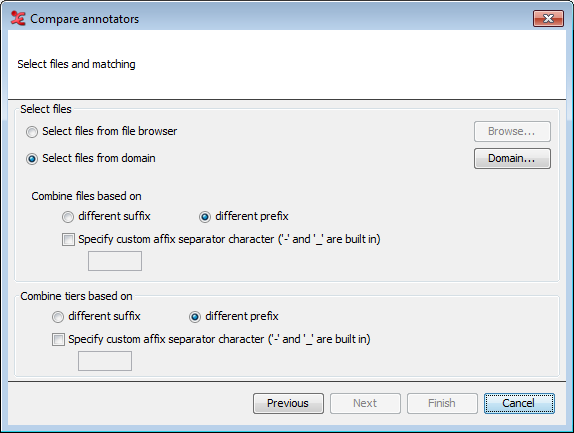 |
The screen above shows all possible options. The options available for this step will differ depending on the configuration you made in the previous step. It will not be available when the option 'in current document' together with 'based on manual selection' was chosen in the previous step.
Select files from file browser Browse for one or more files that you wish to use.
Select files from domain Choose or create a domain of files to use, see the section called “How to select multiple files”.
Combine files based on different suffix/prefix When using multiple files, choose how they should be combined. E.g. if there is a certain naming convention for the files and the annotations of the first annotator are in files like "Recording4_R1.eaf" and those of the second annotator in files like "Recording4_R2.eaf" and suffix has been selected, these files will be combined automatically.
Combine tiers based on different suffix/prefix Similar as with files, when a certain naming convention has been used for tiers of different annotators, they can be combined on the basis of a prefix or suffix, e.g. A_LeftHand and B_LeftHand in case of prefix-based matching.
If Fleiss' kappa was selected and the tiers to compare are in different files, an option is available to create and store new EAF files containing the matching tiers (experimental).
Step 5. Tier selection
Figure 154. 5. Tier selection (current document / manual selection)
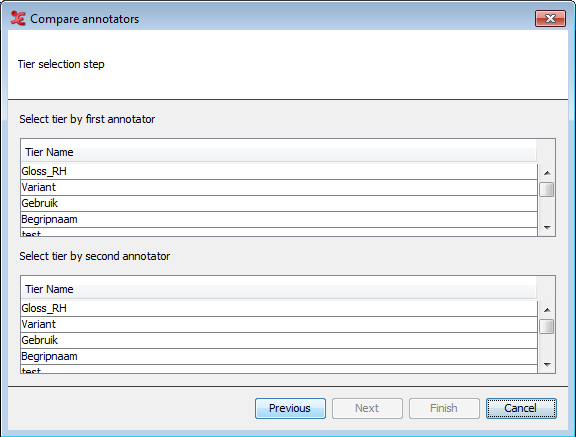 |
In this last dialog, you will select the tiers used for comparison. The layout will be different, based on what you selected in previous steps. The screen above displays the dialog when you've chosen the option 'In the current document' & 'based on manual selection' in step 3. You can manually select which tiers to compare.
Figure 155. Tier selection (in the same file / based on suffix)
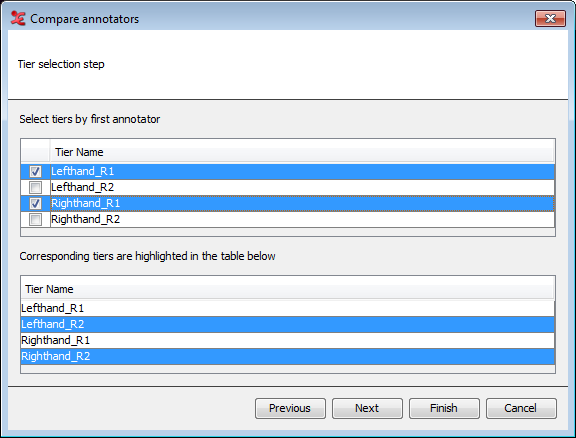 |
The dialog above will appear when 'based on pre/suffix' in step 3 is chosen. Marking a tier from an annotator will result in a highlighted corresponding tier in the lower part of the dialog. When 'based on same tier name' was chosen, you can only select tier names, corresponding tiers will not be visible in the dialog.
Finally, click Next or Finish to save the output text file to a location on your computer.