The Lexicon analyzer
The Lexicon analyzer is a combination of the parse and the gloss analyzer. When a lexical entry matches a part of the input token during the matching process (and thus becomes part of one of the suggestions), the glosses of that entry are added to the suggestions too (these "glosses" can be the from any field of the entry, depending on the tier-typ configuration), By configuring the lexicon analyzer, the source tier containing the annotations will both be parsed and glossed in one action. This analyzer requires one source tier and two target tiers.
![[Note]](images/note_1855015319.png) | Note |
|---|---|
As of ELAN 7.1 (April 2026), it is possible to configure a third target column for the Lexicon analyzer. This third target can be used, for example, for a grammatical category. For all other analyzers this column is disabled. When a third target is configured for the Lexicon analyzer, the Suggestion View will display three target tiers for suggestions produced by this analyzer. |
Figure 353. Lexicon Analyzer settings configuration window
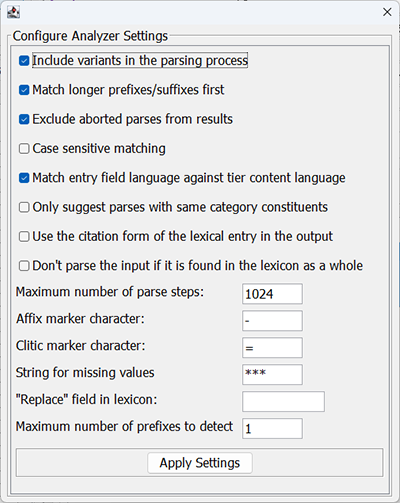 |
The Lexicon analyzer supports the following configurable settings:
if this option is checked the parser will also look at the variant field in the process of matching morphemes from the lexicon with parts of the word or token it has received as input
by default the parser tries to match shorter prefixes before longer ones. This has an effect on the order of the suggestions
if the parser hasn't finished (one iteration of) the matching process within the maximum number of steps, it adds an "++ABORT++" label at the position in the suggestions where it stopped. This option allows to filter them out of the presented results.
tells the analyzer whether or not to ignore case in the matching process
this option allows the analyzer to only include fields with a language string equal to the content language of the target tier (the short id, e.g. "nld" for Dutch). If a lexical entry contains e.g. glosses in multiple languages, only the gloss(es) with the same langauge as the target tier will be suggested.
when this option is selected the analyzer only includes suggestions where the parts have the same grammatical category (based on exact matching, no support for regular expressions yet).
with this option selected the analyzer will use the citation form field in the output (if it exists).
tells the analyzer to first check if the full input text is an entry in the lexicon and, if so, return that entry (or those entries) without further attempts to parse it into affixes and stem etc.
when underlying forms have been defined for the input token (via Add Underlying-Forms), suggestions are generated only from those underlying forms and normal parsing is skipped
this option determines when the parser should stop the matching process to prevent an unusable number of suggestions
by default the analyzer assumes the character that is used to mark a lexical entry as a prefix (a-) or suffix (-a) is a hyphen. This can be changed here (ideally this information should be an accessible property of the lexicon). Apart from this marker, the analyzer has hard coded, built-in support for the morpheme types "prefix", "suffix", "root", "stem" to determine what to try to match in the parsing process.
this field allows to specify the character used to mark clitics in the lexicon. Clitics are treated the same as affixes in the parsing process.
sets the text the analyzer should use to indicate that a part (e.g. a gloss) is missing in the lexicon
this analyzer supports replacement of a matched morph by one or more characters to make the next parse step (more) successful. This replacement text should be in the lexical entry and by default the analyzer looks for a (custom) field "replace". If it is in another field, it can be specified here.
allows to specify a maximum number of prefixes to match by the analyzer. When this maximum is reached, the remaining part of the input will be checked for matching stems and/or suffixes.
Changes in these settings will only be passed to the analyzer after clicking !