Searching in a single annotation file
To search for text, do the following:
Click on menu.
Go to (alternatively you can press CTRL+F) The following dialog window is displayed:
Figure 386. Search dialog
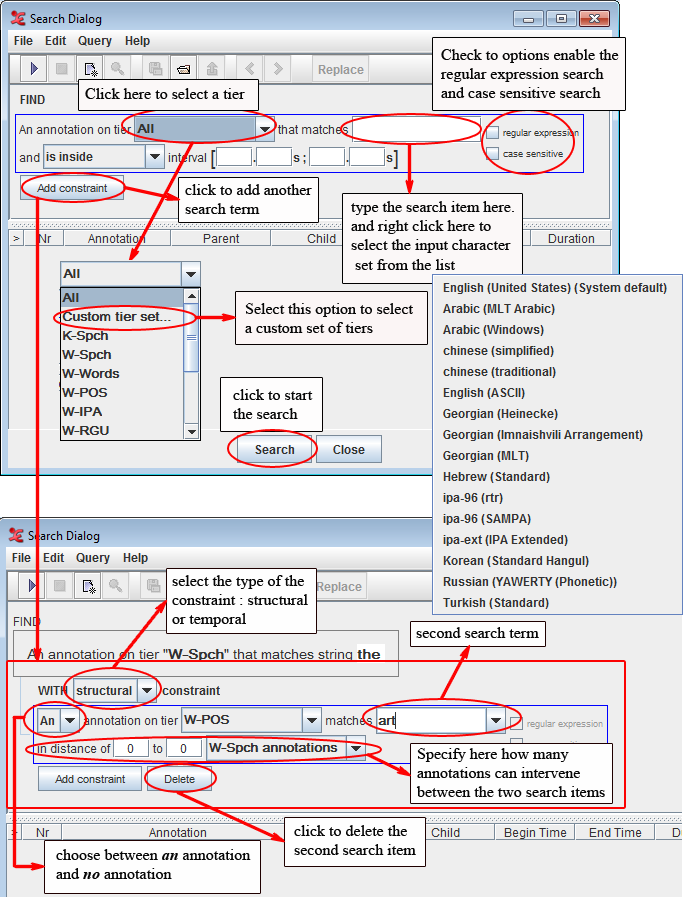
The following search options are available:
Go to and, from the pull-down menu, select the tier to be searched.
Go to and type in the item to be searched. If the tier type of the selected tier has a Controlled Vocabulary (see the section called “Changing the parent of a tier”), this field is a pull down menu containing the entries of the controlled vocabulary. Note that it is still possible to enter a string that is not in the list.
You can always make use of regular expressions to conduct your searches when “regular expression” is checked. (see REGULAR EXPRESSION SEARCH for the regular expression syntax).
By default the search is not case sensitive. To change this, select the “case sensitive” checkbox.
Optionally, specify the interval to search in (from ... s …ms to … s … ms). Make a choice between searching within a time interval and finding annotations that overlap with a certain interval. Click on to add a second tier and search item. Up to 10 constraints can be used. There exist 2 kinds of them:
Constraints based on structural distance. (Annotation units “around” a certain annotation entity). This option is only available for tiers that are symbolically associated to (or are a symbolical subdivision of) the tier mentioned in the first search box.
For example: annotations contained in a structural distance of –1 to 2 tx-annotations from trees on the tier tx are sees, trees, and, flowers.
Table 10. Annotation example
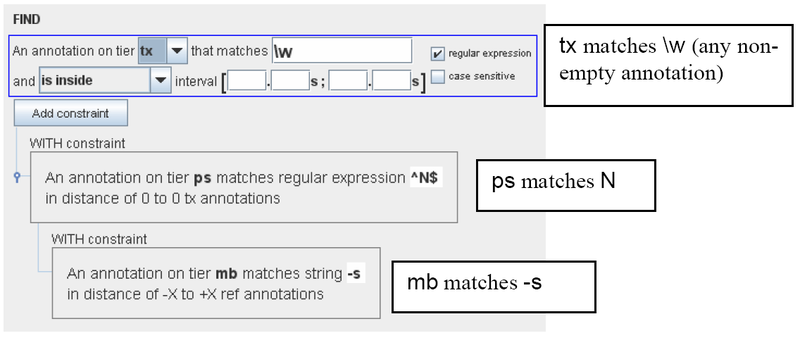
tier annotations st (sentence) He sees trees and flowers. tx (word) he sees trees and flowers mb (morpheme break) … see -s tree -s … flower -s ps (part of speech) … V SUF N SUF … N SUF Constraints based on temporal distance. This means search results are restricted on the basis of the temporal relation between two intervals:
is inside: the annotation is completely contained within a given interval

overlaps: at least a part of the annotation is contained within the given interval
overlaps only begin time of: the annotation only has its end part in common with the given interval

overlaps only end time of: the annotation only has its begin part in common with the given interval

is within … around: the annotation is contained in an interval around either the begin time or the end time

is within … around begin time of: the annotation is contained in an interval around the begin time

is within … around end time of: the annotation is contained in an interval around the begin time

It is possible to search on different tiers within one annotation. For example, the search parameters illustrated below search for all annotations on the tier tx, which contain “-s” in one of their morpheme breaks and “N” in one of their parts of speech. (Both “-s” and “N” are in distance of “0 words”, i.e., they occur within the same word as specified on the tier tx.) I.e., these parameters would find “trees” and “flowers” in the above example, but not “sees”.
Figure 387. Find with constraints
Another option is searching for sequences of utterances, words or other annotations on the same tier, e.g.:
Figure 388. Find sequences

You can delete the second (or third) search item. Click on to delete it.Right click in a text box to change the input character set and select the suitable language from the pull-down menu.
You only need this option if you want to select a non-default character set. The box automatically displays the default set of the selected tier (see the section called “Changing tier attributes”).
After you have specified your search parameters, click to start the search process.
![[Note]](images/note_1855015319.png) | Note |
|---|---|
Make sure the box next to Regular Expression is checked when you search for “special” characters (i.e. all characters that are not plain letters or digits) like diacritic characters. |