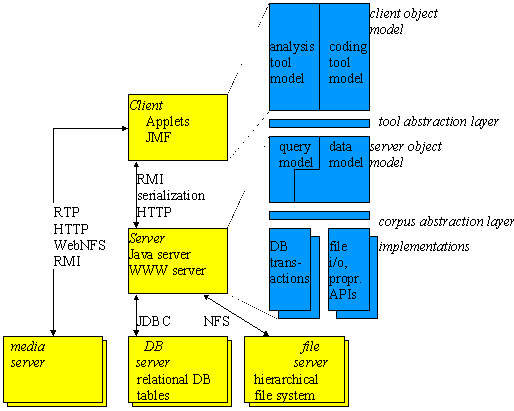
The basic architecture of EUDICO is shown in the following figure:
The yellow components denote logical servers/services. A user working on a client first interacts with the help of a browser with a Web-server. When the EUDICO home page is loaded the main EUDICO applet is loaded and started from the client's browser. This applet now starts communicating with a Java server application using RMI. It can request all kinds of information about corpus data from the server when needed. The applet is also capable of requesting segments of audio or video data from a media server directly. Corpus annotation data from the Java server and media data from the media server can be played back synchronously in time on the client with the help of the Java Media Framework (JMF). 'Streaming' media data to the client can be done using a range of available protocols.
The blue components indicate software models. The basis of the EUDICO architecture is what we call a "common model of linguistic corpora" which we got by carefully analyzing a range of formats which are relevant for our work. This model captures the functional equivalence of a range of elements that occur in most corpora (e.g. most corpora contain transcriptions or documents that can have multiple annotation layers/tiers, so it makes sense to have an operation on transcriptions called "getTiers"). This "common model" is depicted in the figure as "data model". To the client the common model offers uniform services for each corpus element irrespective of what corpus the element comes from. All such services offered to clients taken together are called "tool abstraction layer".
On the server, the services of the "tool abstraction layer" are implemented differently for each supported corpus. Specific implementations of objects can be loaded from widely different existing resources: from relational databases using JDBC, from plain text files on filesystems accessible locally or over NFS, or from proprietary systems accessible using a specific API (Application Programming Interface). Currently we have made implementations of all of these three types. The minimal set of all services that have to be implemented specifically for each corpus is called "corpus abstraction layer".
Finally, object models for the main types of client software tools exist and are implemented.
In a next version of EUDICO we will support distribution of the functions of the Java server and the media server over different machines on different locations, making EUDICO a truely distributed system.