The following analyzers are distributed with ELAN:
Parse Analyzer
Gloss Analyzer
Lexicon Analyzer (a combination of the Parse and Gloss analyzers)
Whitespace Analyzer
The names are somewhat misleading; all of the Parse, Gloss and Lexicon analyzers require access to a lexicon. The Parse analyzer morphologically parses annotations from a word (or token) level tier, based on lexical units (prefixes, stems, suffixes etc.) available in the lexicon (internally the parser is implemented as a state machine with a stack). The results are shown as parse suggestions in a suggestion window from which the user can select one. This analyzer requires one source tier and one target tier, where the target is of a subdivision tier type.
The Gloss analyzer looks up the source annotation in the lexicon and lists all glosses found in the matched entries. The results are again presented as suggestions from which the user can select one. This analyzer requires one source tier and one target tier, where the target is of a symbolic association tier type.
The Lexicon analyzer is a combination of the parse and the gloss analyzer. By configuring the lexicon analyzer, the source tier containing the annotations will both be parsed and glossed in one action. This analyzer requires one source tier and two target tiers.
The Whitespace analyzer splits the selected source annotation at white spaces and places the result on the target tier. It does not need any user confirmation. This analyzer requires one source tier and one target tier, where the target is of a subdivision tier type. Currently the behavior of this analyzer can not be configured (e.g. with respect to treatment of punctuation marks), this might be added in the future.
When configuring analyzers and their source and target tiers, it is possible that the target tier from one analyzer, is the source tier for the next analyzer. The configuration of the tiers is based on tier types rather than on individual tiers.
![[Note]](images/note.png) | Note |
|---|---|
Configuration on the basis of individual tiers might be added later as an option as well. |
The Lexicon analyzer is a combination of the parse and the gloss analyzer. When a lexical entry matches a part of the input token during the matching process (and thus becomes part of one of the suggestions), the glosses of that entry are added to the suggestions too (these "glosses" can be the from any field of the entry, depending on the tier-typ configuration), By configuring the lexicon analyzer, the source tier containing the annotations will both be parsed and glossed in one action. This analyzer requires one source tier and two target tiers. (The LEXAN API currently limits the number of target tiers to two, this might be too restrictive and may need to be reconsidered in a future release.)
The Lexicon analyzer supports the following configurable settings:
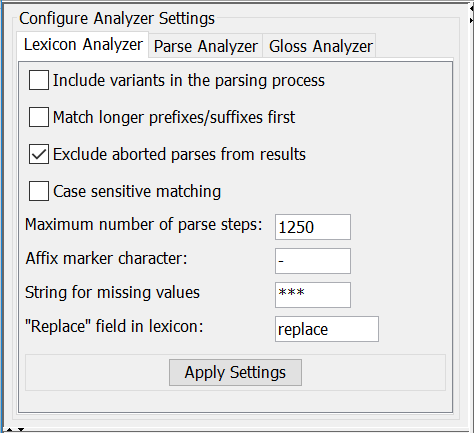
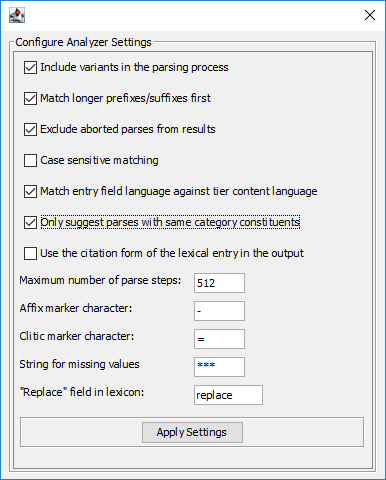
if this option is checked the parser will also look at the variant field in the process of matching morphemes from the lexicon with parts of the word or token it has received as input
by default the parser tries to match shorter prefixes before longer ones. This has an effect on the order of the suggestions
if the parser hasn't finished (one iteration of) the matching process within the maximum number of steps, it adds an "++ABORT++" label at the position in the suggestions where it stopped. This option allows to filter them out of the presented results.
tells the analyzer whether or not to ignore case in the matching process
this option allows the analyzer to only include fields with a language string equal to the content language of the target tier (the short id, e.g. "nld" for Dutch). If a lexical entry contains e.g. glosses in multiple languages, only the gloss(es) with the same langauge as the target tier will be suggested.
when this option is selected the analyzer only includes suggestions where the parts have the same grammatical category (based on exact matching, no support for regular expressions yet).
with this option selected the analyzer will use the citation form field in the output (if it exists).
this option determines when the parser should stop the matching process to prevent an unusable number of suggestions
by default the analyzer assumes the character that is used to mark a lexical entry as a prefix (a-) or suffix (-a) is a hyphen. This can be changed here (ideally this information should be an accessible property of the lexicon). Apart from this marker, the analyzer has hard coded, built-in support for the morpheme types "prefix", "suffix", "root", "stem" to determine what to try to match in the parsing process.
this field allows to specify the character used to mark clitics in the lexicon. Clitics are treated the same as affixes in the parsing process.
sets the text the analyzer should use to indicate that a part (e.g. a gloss) is missing in the lexicon
this analyzer supports replacement of a matched morph by one or more characters to make the next parse step (more) successful. This replacement text should be in the lexical entry and by default the analyzer looks for a (custom) field "replace". If it is in another field, it can be specified here.
Changes in these settings will only be passed to the analyzer after clicking !
This analyzer is largely the same as the parser part of the Lexicon analyzer, with the same configurable settings. It does not support the option, which belongs to the glossing part of the process.
This analyzer performs a look-up of the input token in the lexicon and returns all values of the lexical entry field it is configured for (via the tier type). This doesn't have to be the "gloss" field of the lexical entries, but can be any field.
This analyzer supports the following configurable setting:
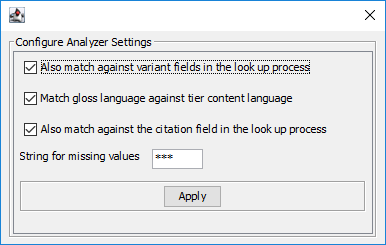
if this option is checked the glosser will also look at the variant field in the process of matching the input
this option allows the analyzer to only include glosses with a language string equal to the content language of the target tier (the short id, e.g. "nld" for Dutch). If a lexical entry contains e.g. glosses in multiple languages, only the gloss(es) with the same langauge as the target tier will be suggested.
with this option selected the analyzer will use the citation form field in the output (if it exists).
sets the text the analyzer should use if the specified field is not found in matched entries in the lexicon
This analyzer splits the input text it receives into multiple tokens based on white spaces. It allows to configure how e.g. punctuation marks should be treated.
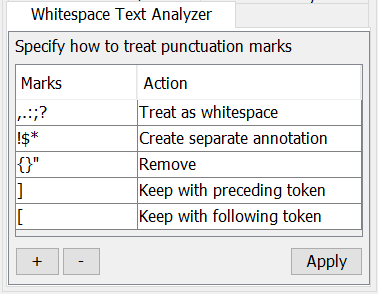
The and buttons can be used to add or remove a category of characters, represented by a row in the table. A category can contain one or more characters; if there are more than one, each character is separately treated according to the setting for that category. The table has two columns, one labelled Marks, where the special characters or marks can be entered, and one labelled Action, specifying the way those characters should be handled in the tokenization process. When clicked on, the second column shows a dropdown list with predefined actions:
Treat as white space means that the input will be split at the position of this character and that this character itself will not be in the output
Create separate annotation means that the input will be split at this position and that this character will become a separate token (annotation) in the output
Keep with preceding token means that this character will become part of the same annotation as the characters to the left of it
Keep with following token means that this character will become part of the same annotation as the characters to the right of it
Remove means that this character will be removed from the input string without causing a split of the input (i.e. it is filtered out)
The button has to be clicked to inform the analyzer of the changes and to put them into effect.