The Gloss analyzer
This analyzer performs a look-up of the input token in the lexicon and returns all values of the lexical entry field it is configured for (via the tier type). This doesn't have to be the "gloss" field of the lexical entries, but can be any field.
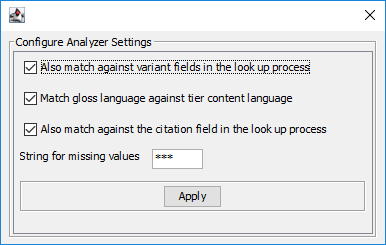
Figure 354. Gloss Analyzer settings configuration window
 |
This analyzer supports the following configurable setting:
if this option is checked the glosser will also look at the variant field in the process of matching the input
this option allows the analyzer to only include glosses with a language string equal to the content language of the target tier (the short id, e.g. "nld" for Dutch). If a lexical entry contains e.g. glosses in multiple languages, only the gloss(es) with the same langauge as the target tier will be suggested.
with this option selected the analyzer will use the citation form field in the output (if it exists).
sets the text the analyzer should use if the specified field is not found in matched entries in the lexicon