The Whitespace Text analyzer
This analyzer splits the input text it receives into multiple tokens based on white spaces. It allows to configure how e.g. punctuation marks should be treated.
Figure 355. Whitespace analyzer configuration panel
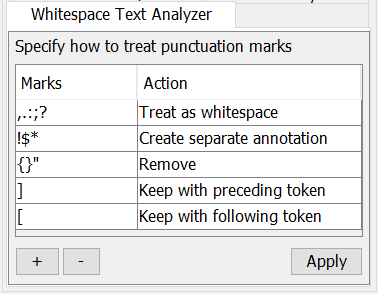 |
The and buttons can be used to add or remove a category of characters, represented by a row in the table. A category can contain one or more characters; if there are more than one, each character is separately treated according to the setting for that category. The table has two columns, one labelled Marks, where the special characters or marks can be entered, and one labelled Action, specifying the way those characters should be handled in the tokenization process. When clicked on, the second column shows a dropdown list with predefined actions:
Treat as white space means that the input will be split at the position of this character and that this character itself will not be in the output
Create separate annotation means that the input will be split at this position and that this character will become a separate token (annotation) in the output
Keep with preceding token means that this character will become part of the same annotation as the characters to the left of it
Keep with following token means that this character will become part of the same annotation as the characters to the right of it
Remove means that this character will be removed from the input string without causing a split of the input (i.e. it is filtered out)
The button has to be clicked to inform the analyzer of the changes and to put them into effect.