ELAN supports importing file from :
Toolbox file (Section 1.4.2.1)
Fieldworks Language Explorer (FLEx) file (Section 1.4.2.2)
CHAT file (Section 1.4.2.3)
Transcriber file (Section 1.4.2.4)
CSV / Tab-delimited Text file (Section 1.4.2.5)
Subtitle Text or Audacity Label file (Section 1.4.2.6)
Praat TextGrid file (Section 1.4.2.7)
WebAnnotation JSON file (Section 1.4.2.8)
Tiers from recognizer (Section 1.4.2.9)
Shoebox file (Section 1.4.2.10)
There are also options in ELAN available to import multiple files at once. More details regarding these options can be found here: Section 1.9.4
ELAN supports the import of documents from Toolbox, allowing you to link transcribed and/or interlinearized documents to the time axis of media files. In order to import from Toolbox, you need at least the following two files:
the Toolbox file (
*.txt, *.sht, *.tbt);the media file(s) (
*.mpg,*.mov,*.wavetc.);
Optionally you can use the corresponding Toolbox database type file
(*.typ). If this is not available, one has to provide a list
with field markers (= tier names).
![[Note]](images/note.png) | Note |
|---|---|
If you do not know the Toolbox database type file, do the following:
|
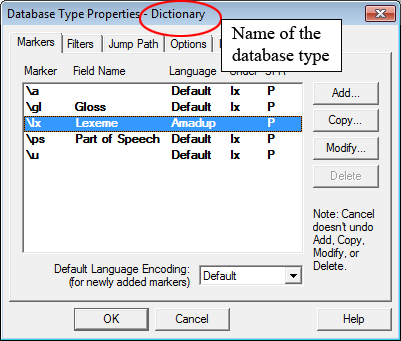
Importing Toolbox files with a TYP file
To import a Toolbox file into ELAN, do the following:
Click on . The dialog box appears.
Specify the name and directory of the two files, e.g.:
Like
*.eafdocuments, the Toolbox file and the media file(s) do not necessarily need to have the same name, and they do not need to be in the same directory (see Section 1.1).If the Toolbox file contains both aligned (i.e. containing time information) and non-aligned records, the aligned ones will maintain the timing, whereas the location of the non-aligned records will be interpolated automatically.
Click to import the file; otherwise click to exit the dialog box without importing the file.
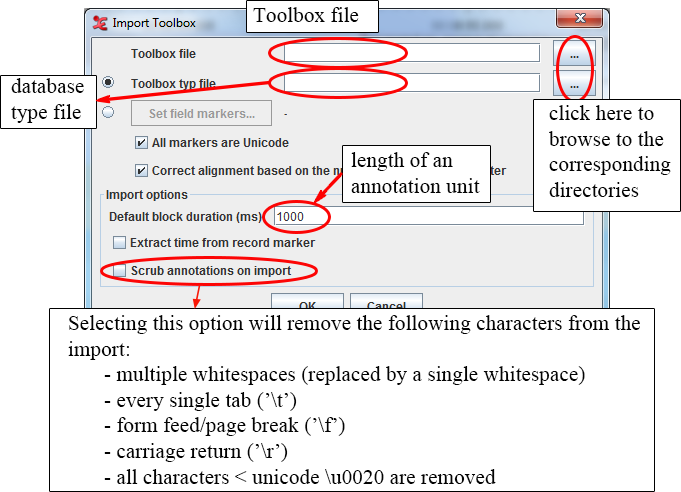
An ELAN window containing the imported Toolbox file appears.
Importing Toolbox files without a TYP file
Instead of using a Toolbox *.txt file, there is also an option in ELAN to define the field
markers yourself when importing a Toolbox file.|*.sht |*.tbt
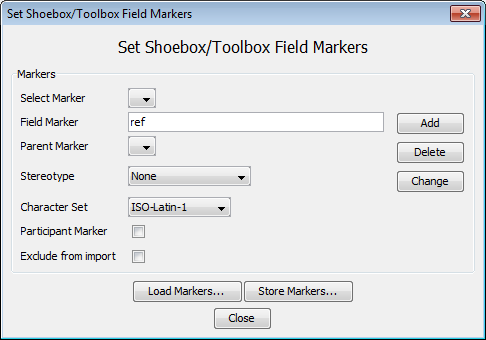
select the Set field markers and click on the button in the import dialog. The following window appears:
Now fill in a field marker as used in the Shoebox/Toolbox
*.txtfile|*.sht |*.tbtOptionally select a parent marker (see Section 2.1)
Optionally select a stereotype (symbolic subdivision or association, see Section 2.1)
Choose a character set (Latin-1, SIL IPA or UTF-8) for the tier (only available with Shoebox import! Toolbox charset is UTF-8)
Click on Add.
Repeat step 2-6 for all field markers.
If the selected marker designates a participant, check the checkbox. If you don’t want the selected marker to be imported, tick .
finally choose and click on in the import Shoebox file dialog
| Note |
|---|---|
Some markers are already 'built-in' in ELAN and must not need to be set: ELANBegin, ELANParticipant, ELANEnd. |
Loading and storing Markers
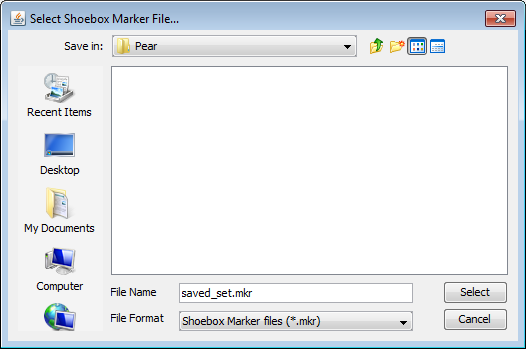
Once you have manually created a set of field makers, you might want to reuse them later on. ELAN provides support for this:
To save a set of field markers, select the button. This will display a save dialog. Enter a file name, and press save.
The same way you can open a stored field marker set by clicking on
Connecting the transcription to a media file
Once the import has succeeded, you can add a reference to a media file via the menu, as described in Section 1.2.14. If the imported Toolbox file was exported from ELAN before, you won’t need to establish the link to the media file(s) again, as in that case the location information is stored in the file.
About the import process
ELAN imports Toolbox files according to the following conventions:
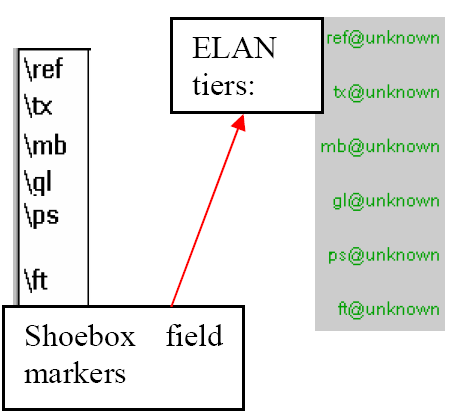
The Toolbox field markers are imported as ELAN tiers. The tier label is identical to that of the field marker, except for the added extension @‘Speaker-ID’.
This addition is necessary because ELAN and Toolbox differ in how they code information about multiple speakers:
In ELAN, each speaker is coded on a separate tier.
In Toolbox, all speakers are coded using the same field, and their identity is specified in a separate field.
When importing texts by multiple speakers, ELAN splits each Toolbox field into several ELAN tiers (one for each speaker) and adds the speaker-ID to the tier label.
If speaker information is not specified in the Toolbox file, the extension @unknown is added.
The following screenshot illustrates how ELAN treats texts by multiple speakers:
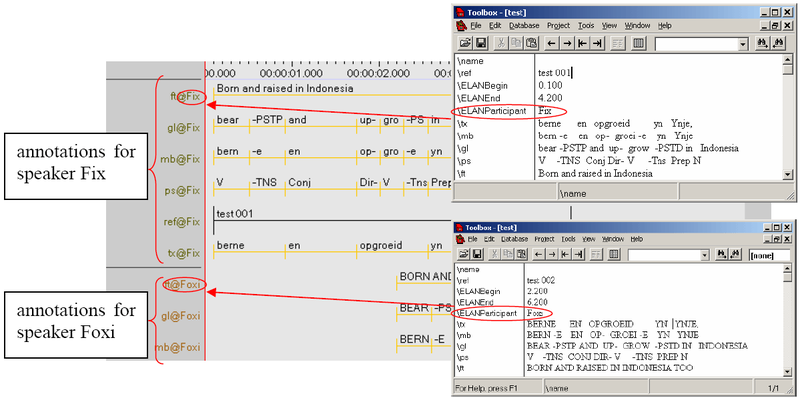
Note that ELAN can only read speaker information if:
A marker is defined as a Participant marker in the Set field marker dialog (see Importing Toolbox files without a TYP file above), or if:
It is coded in a Toolbox field labelled \EUDICOp or \ELANParticipant (see illustration above). If this field is not present, or if speaker information is coded in a different field, ELAN will assume that there is only one speaker. I.e., if you have multiple speakers and if you want ELAN to assign them to separate tiers, do the following:
For every Toolbox record, add the field marker \EUDICOp.
For every Toolbox record, enter the relevant speaker-ID into this field.
| Note |
|---|---|
When the file is exported back to Toolbox (see Section 1.4.1.2), the extension @‘Speaker-ID’ is automatically dropped from the field marker, and the Toolbox records are sorted according to their record marker (e.g., in the above illustration, “test 001” is sorted before “test 002” etc.) |
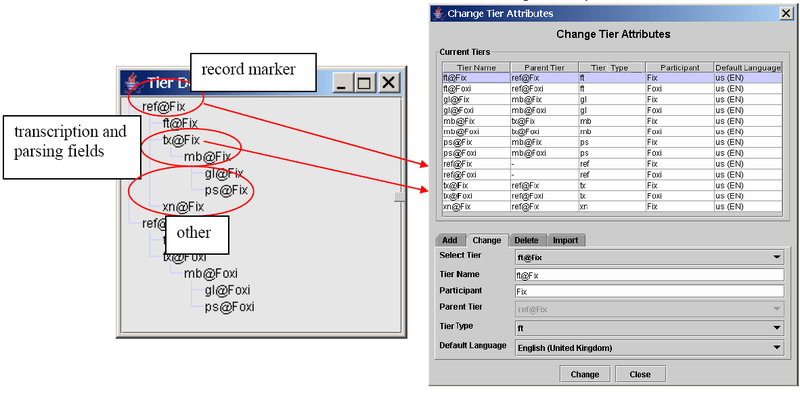
Based on the information contained in the Toolbox database type file, the tiers are brought into a hierarchical relationship and are assigned to tier types (see Section 2.1 for details of tier hierarchies and tier types). For every tier name a corresponding tier type with the same name is created. All of these tier types are connected with a stereotype in such a way that it fits with the original Toolbox structure.
The Toolbox record marker is assigned to the stereotype None, i.e., it is an independent, time-alignable parent tier.
The transcription and parsing fields of Toolbox are assigned to the stereotype Symbolic Subdivision, i.e., they are referring tiers that can be subdivided into smaller units.
All other fields are assigned to the stereotype Symbolic Association, i.e., they are referring tiers that cannot be subdivided into smaller units.
If you define the markers yourself, then there also is the possibility to choose the Time Subdivision stereotype. For example:
If you import a Shoebox record, all SIL IPA characters are converted into Unicode characters during import. If you export the file back into Shoebox (see Section 1.4.1.22), the Unicode characters will be converted back into SIL IPA characters. This does not apply to Toolbox records.
Initially, unless it had the time code information, the imported Toolbox file does not contain information about timing. Instead, ELAN automatically assigns each Toolbox record to a three second time interval, as in the following illustration:
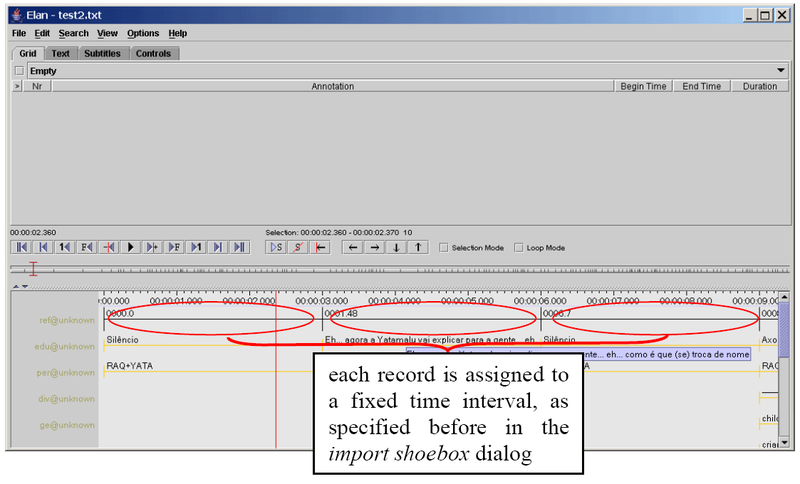
The time alignment has to be done manually for each Toolbox record. Do the following:
Activate the Bulldozer mode: Click on (see Section 2.8.9 for the three available modes).
Note If you do not activate the Bulldozer mode, you will inadvertently overwrite and thereby delete existing annotations. Make sure that is enabled in the menu.
Click on the first annotation on the parent tier (i.e., the first Shoebox record). It appears in a dark blue frame.
Modify the boundaries of that annotation, so that they are aligned with the correct time interval (see Section 2.8.7 for ways of modifying boundaries).
Press CTRL+ENTER to apply the new time interval.
The parent annotation (together with all its referring annotations) is assigned to the new time interval. All other parent annotations are moved to the right.
Repeat steps 2 to 4 for each parent annotation.
The following screenshot illustrates steps 1 to 4:

After you have done the time-alignment, you can export the file back to Toolbox – in this case, the time code information will be kept (see Section 1.4.1.2). If you then re-import the file back into ELAN, ELAN automatically assigns the Shoebox records to their correct time intervals.
An imported Toolbox file can be saved as an ELAN file (see Section 1.2.7), exported back into Shoebox (see Section 1.4.1.2), or exported as a tab-delimited text (see Section 1.4.1.5).
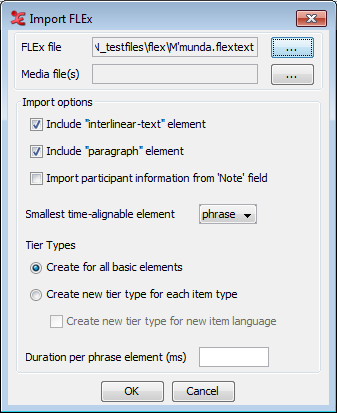
ELAN can import documents from the SIL Fieldworks Language Explorer (FLEx). This involves a few steps:
Click . Select the
.flextextfile and relevant media files by clicking the -buttons.In the import window select the
.flextextfile exported from FLEx. Optionally also add media files here (if not already in your.flextextfile). There are options to exclude theinterlinear-textandparagraphelements from the import, as well as the option to import participant information. When as smallest time-alignable element thewordelement is selected, the time-alignment for that level will be lost when exported again to FLEx. In.flextexttime alignment is stored on thephraselevel.It is possible to have tier types created simply for all major elements (
phrase,word,morphetc.) or, more fine-grained, for each combination of major element plusitem typeup to a combination of major element, the type and the language.Finally, set a duration per
phraseelement in milliseconds. This has to be set if the FLEx export files do not contain timestamps. When importing a FLEx file that was edited in ELAN before and exported as a.flextextfile, time duration information has already been stored in the file.

The tier structure created after import in ELAN is roughly like in the example above. The mapping of the FLEx structure onto ELAN tiers follows the schema: <Speaker>_<element>-<item-type>-<language> Where the Speaker prefix is a generic label (A, B, C, ...).
FLEx tiers and their representation in .flextext:
| Word | <word> | <item type=”txt”> |
| Morphemes | <morph> | <item type=”txt”> |
| Lex. Entries | <morph> | <item type=”cf”> |
| <morph> | <item type=”hn”> | |
| Lex. Gloss | <morph> | <item type=”gls”> |
| Lex. Gram. | <morph> | <item type=”msa”> |
| Word Gloss | <word> | <item type="gls"> |
| Word Cat. | <word> | <item type=”pos”> |
| Note |
|---|---|
On the third-party resources page of ELAN (https://archive.mpi.nl/tla/elan/thirdparty ), you can find a workflow description covering importing from FLEx to ELAN and back to FLEx. |
It is possible to import CHAT files (used in e.g. the Childes project) in ELAN:
Select
Select the Chat file
Click on
Some remarks about this import feature:
supported are old CHAT files and CHAT-UTF8, not XML CHAT
existing media alignment in %snd tiers is maintained in ELAN:
when no media alignment is present at all, each CHAT utterance gets a default interval of 1 second assigned
when partial media alignment is present, the time interval is equally distributed over preceding unaligned utterances
overlapping utterances of the same participant are corrected as good as possible
CHAT dependent tier names are mapped to ELAN Tier Types
ELAN tier names are either CHAT participant labels or CHAT tier names, followed by '@participantName'
Remaining issues:
'<' and '>' characters in CHAT cause parsing errors when the imported file is saved as EAF file
The feature to import Transcriber annotation files into ELAN works as follows:
Choose
Select the transcriber file (
*.trs) and click on OpenIf the associated sound file cannot be found, a dialog will be shown asking you to locate it. When this request is cancelled, one can choose to open the annotation file without the sound, or to stop the whole import process.
The transcriber tiers will be mapped on the ELAN equivalents:
Section becomes a independent tier and turn becomes a referring tier of section (see also Section 2.1).
Events are embedded into the annotation text.
A CSV (Comma Separated Values) or Tab-delimited Text (or Tab Separated Values) file is a text file in which one can identify rows and columns. Rows are represented by the lines in the file and the columns are created by separating the values on each line by a specific character, like a comma or a tab. CSV or Tab-delimited Text files can be compared to spreadsheets like the ones in Microsoft Excel in that they also have rows and columns. Note that .csv files can be created by Excel.
Take a look at Figure 1.68. The first row represents the event of a person saying 'so from here'. The first value (as well as the first column of the complete file) represents the tier name, the second and third represent begin time in different formats, the fourth and fifth represent the end time, the sixth an seventh represent the duration and the last value represents the annotation.

You are able to import CSV or Tab-delimited Text files in ELAN: . In the dialog window browse to and select a file that contains CSV or Tab-delimited data and click .
The second dialog window contains two sections (see Figure 1.69). The upper section shows a sample table containing data from the selected file. Both rows and columns are numbered. The lower section enables you to specify which columns to include and what data type they represent. This means that the format of the files is flexible: it is not prescribed what data is expected nor how it is formatted. The numbers of the columns in the Import Options section correspond to the numbers of the columns in the sample table. The data types you can select are:
Annotation
Tier
Begin time
End time
Duration
Select at least one column with data type 'Annotation'. If you select a column for begin time, end time and duration, the latter will be ignored in the import process.
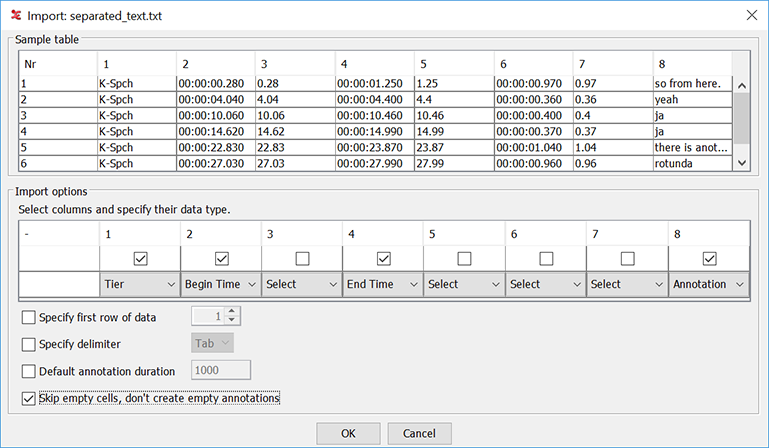
The option Specify first row of data enables you to exclude a
header by excluding the first few lines. The option Specify delimiter
lets you specify the delimiter if ELAN did not guess the correct delimiter. The
delimiters supported by ELAN are comma, tab, colon, semi-colon and the vertical line
(vertical bar).
If you enable the option Default annotation duration ELAN creates
all annotations from the selected file with durations equal to the number of
milliseconds specified. This option works only if there is no time data or only the
begin or end times.
Default annotation duration will create annotation units with the
specified duration.
Skip empty cells will leave out the cells in the csv that are
empty. Different tiers can be imported with different segmentations with this option.
Finally click to import the data. If a transcription document was open when starting the import, the imported tiers and annotations will be added to the already open document, otherwise a new transcription document is created with the imported annotations as its contents.
Another example
To demonstrate that the format of the imported file can be flexible, take a look at the following tab-delimited text:

In this example each column represents a tier with the tier names in the
first row and the annotation in the other rows. This file can be imported by selecting
the following import options:
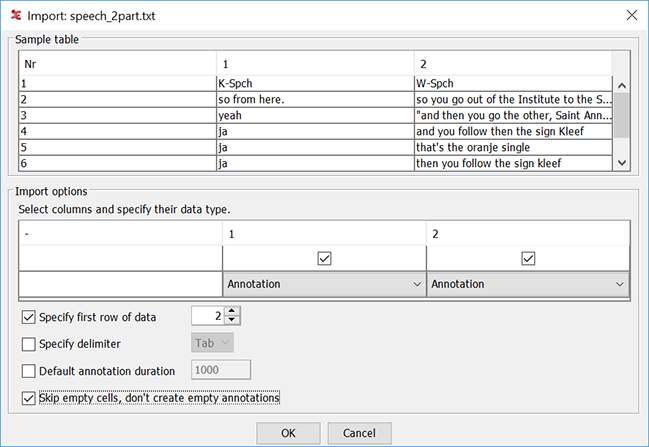
Note that the Specify first row of data option is set to 2.
As a consequence ELAN starts importing annotations from row 2 instead of row 1.
Furthermore, ELAN tries to extract tier names from the first line of the file if the
column they are part of is specified as 'annotation'. This results in this example in
two tiers: K-Spch and W-Spch.
To merge a CSV file with an existing *.eaf file, open the
*.eaf file first and then choose . For information on merging a CSV file
that has been imorted into a new document with an existing *.eaf file, please seeSection 1.2.12.
It is possible to import subtitles that are stored in the SubRip
*.srt format: . HTML and similar formatting tags are filtered
out and multiple speakers are merged into one. The correct encoding of the file has to
be specified in the import window.
Audacity Label files are a specific kind of tab-delimited text
(*.txt) files. They can be imported here without the
configuration step that is part of the general import.
If this import is started when a document is already open, the imported contents is added to that transcription. Otherwise a new transcription document is created.
ELAN offers the possibility to import a Praat TextGrid file: click on . In the dialog window that now appears, you can browse to the file you wish to import. You are also able to include Praat PointTiers. When selecting this option, specify the default PointTiers annotation duration in milliseconds. Finally, check Skip empty intervals / annotations if you want to do so.
If there is already a annotation document opened in ELAN, the imported TextGrid is added to the document in one or more new tiers. If there is no annotation document opened, a new document consisting of the TextGrid data is generated.
In addition to TextGrid files in the default encoding for the operating system, ELAN supports Praat TextGrid files with UTF-8 and UTF-16 encoding.
It is possible to import a WebAnnotation JSON file via , the file extension is
.json or .jsonld. There are no
configuration options. The contents of the file should comply with the W3C Web Annotation Data
Model specifications, even though the import function only supports a subset
of those specifications (those elements that map quite naturally to ELAN elements).
Importing Tiers from recognizers will import the tiers in a new file if there is no file currently open in elan. But if a file is open, the tiers will be in the currently open file. To import the tiers from recognizers, go to > > . Selecting this option, first will prompt for the import file. If there is no file is open, the tiers are directly imported to the new file. But if a file is already open, then a 'Create tiers from segments' dialog appears. For more information about this dialog see Figure 2.14.
Importing a document from Shoebox is very much the same as importing a document
from Toolbox (see Section 1.4.2.1). As with
the Toolbox import, information about the tier relations can be provided by means of a
.typ file or by using a marker file.
When reconstructing the vertical alignment of words on interlinearized markers, the position is recalculated based on the number of bytes per character. But in some files this leads to incorrect alignment, therefore this recalculation can be turned off by unchecking Correct alignment based on the number of bytes per character. This import also tries to take non-spacing characters into account.