You can use the ELAN program for annotating your data. This annotation process involves three steps: defining tier types and tiers (see Section 2.3.1 and Section 2.4), selecting time intervals (see Section 2.8), and entering annotations (see Section 2.9).
The following illustration shows an example of an annotation document:
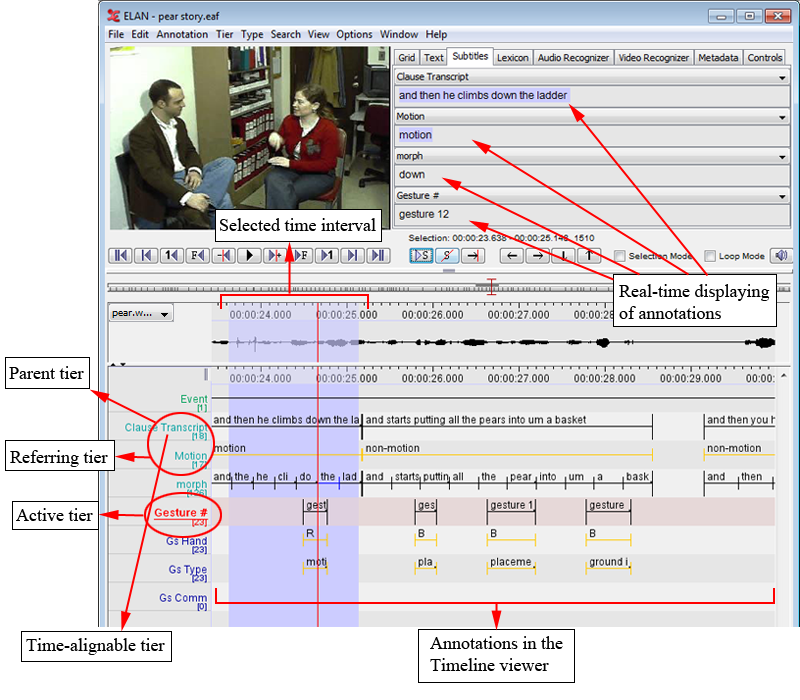
Each annotation is entered on a tier and assigned to a time interval (either
directly or to the time interval of another annotation).
All tiers can be displayed simultaneously in the Timeline or Interlinear Viewer (Section 1.5.13), but four of them can be displayed additionally in the Subtitle Viewer. It is useful to select the tier you are currently working on in a Subtitle Viewer because this viewer is bigger and supports line wrapping (which makes it easier to read along during playback).
It is also possible to select one tier as the active tier. This can be done by double clicking on the tier name in the Timeline or Interlinear Viewer. When a tier is active, its name is underlined and displayed in red. Adding a new annotation to a tier by the keyboard shortcut ALT+N is only possible when that tier is active (see Section 2.9).
A tier is a set of annotations that share the same characteristics, e.g., one tier containing the orthographic transcription of the speakers utterances, and another tier containing the free translation of these utterances.
The following two types of tiers exist:
Independent tiers, which contain annotations that are linked directly to a time interval, i.e., they are “time-alignable”.
Referring tiers, which contain annotations that are linked to annotations on another tier (i.e., to annotations on their so-called “parent tier”). They are usually not linked directly to the time axis. (Some of them may be linked – but only within the time interval determined by their independent parent tier, see below.)
One example: a transcription tier could be independent and time-alignable, as it is linked directly to the time intervals of the speakers utterances. A translation tier, by contrast, would be referring and not time-alignable: it refers to the transcription tier – not directly to the time axis. By definition, it inherits its time alignment from the transcription tier, i.e., from its parent tier.
In the Timeline and Interlinear Viewers, the label of a referring tier is assigned the same color as the label of its independent parent tier.
It is possible to build up nested hierarchies, i.e., tier A can be the parent tier of tier B, and tier B can be the parent tier of tier C, etc.
For example:
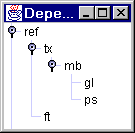
Table 2.1. Nested tier dependencies
| tier: | type: | hierarchical relation: |
|---|---|---|
| ref (referent) | independent | parent of tx and ft |
| tx (text) | referring | parent of mb |
| mb (morpheme break) | referring | parent of gl and ps |
| gl (gloss), ps (part of speech) | referring | - |

![[Note]](images/note.png) | Note |
|---|---|
Parent and child tiers are linked in such a way that some changes made on a parent tier will also affect its child tiers (but not vice versa): |
If you delete a parent tier, all its child tiers are automatically deleted as well. Similarly, when you delete an annotation on a parent tier, all corresponding annotations on its child tiers are deleted as well.
If you change the time interval of an annotation on a parent tier, the time interval of the corresponding annotation on all its child tiers are changed accordingly. The time interval of a child tier cannot be changed independently.
You can view the existing dependency relations by clicking on menu, and then on .
Each tier is assigned to a tier type (see also Section 2.4). A tier type denotes the linguistic data that is contained in the referring tier. Examples of names for tier types are utterances, words, orthography, phonetic transcription, PoS (part of speech), but any name can be used. Each tier type specifies a number of constraints that hold for all tiers assigned to that type. Such constraints are bundled into so-called ‘stereotypes’. The following five stereotypes are currently available:
Table 2.2. Tier type stereotypes
| The annotation on the tier is linked directly to the time axis, i.e., the annotation is entered on an independent tier. Two annotations cannot overlap. Tiers of this type are independent tiers (cannot have a parent tier). | |||
|
The annotation on the parent tier can be sub-divided into smaller units, which, in turn, can be linked to time intervals. Note that there are no time gaps allowed, i.e., the smaller units have to immediately follow each other. Tiers of this type are dependent tiers (must have a parent tier). E.g., an utterance transcribed on a parent tier can be sub-divided into words – each of which is then linked to its corresponding time interval.
| |||
|
Similar to Time Subdivision, except that the smaller units cannot be linked to a time interval. The smaller units form a chain (an ordered sequence) of units. Tiers of this type are dependent tiers (must have a parent tier). E.g., a word on a parent tier can be sub-divided into individual morphemes (which are not linked to a time interval). | |||
|
All annotations on a tier of this type are linked to the time axis and are enclosed within the boundaries of an annotation on the parent tier. However, there can be gaps between the child annotations (unlike Time Subdivision). Tiers of this type are dependent tiers (must have a parent tier). E.g., a sentence with a silence can be split up into words while the silence corresponds to a gap in the child annotations (i.e. the separate words). | |||
|
The annotation on the parent tier cannot be sub-divided further, i.e., there is a one-to-one correspondence between the parent annotation and its referring annotation on this tier. Tiers of this type are dependent tiers (must have a parent tier). E.g., one sentence on a parent tier has exactly one free translation. Or one word has exactly one gloss. | |||
[a] A similar stereotype exists in Media Tagger, so it is especially useful for the import of such files. | ||||
The following example illustrates (four of) the different stereotypes (see also Figure 2.3):
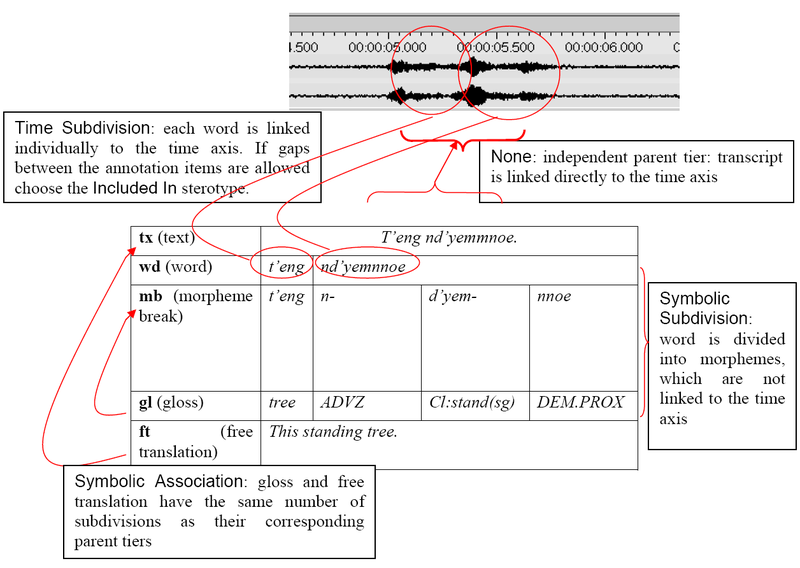
You can define an unlimited number of tiers. It is useful to make decisions about
the type of information that you want to enter (and consequently about the type of tiers
that you need) at a relatively early stage in the annotation process. However, it is
always possible at a later stage to change the parent of a dependent tier (see Section 2.4.9) or to copy a tier (Section 2.13.2) and to alter the copy.