The main concept underlying AMS is the corpus tree. The corpus consists of nodes and arcs that form a tree-like structure representing the corpus hierarchy. Each node can group other nodes on the basis of, e.g., the geographical region, the discourse genre, the sex or age of the speaker, the dialect of the speaker, the source/target language etc. The lowest level in the hierarchy consists of the actual resources (see Section 1.1.1.2). Consider the following example:
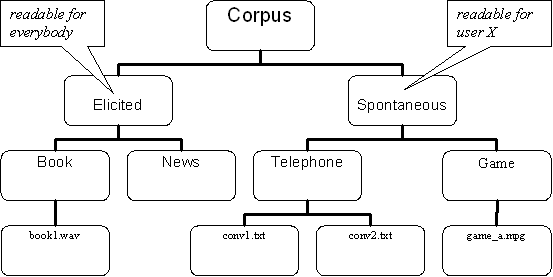
The node labeled 'Corpus' is the top node. The nodes labeled 'Elicited' and
'Spontaneous' are subnodes. These subnodes are sometimes called 'children' of the node
above them, in this case the top node 'Corpus'. The nodes 'Book' and 'News' are children
of the node 'Elicited' and grandchildren of 'Corpus'. Similarly, the nodes 'Telephone' and
'Game' are children of 'Spontaneous' and also grandchildren of 'Corpus'. The nodes labeled
with filenames like book1.wav and game_a.mpg are
at the lowest level and represent the resources.
By using this hierarchical data representation you can specify access rights in the form of rules (see Section 1.1.2) for a certain branch of the tree. A branch consists of a node plus all of its descendants. Therefore, a rule does not only apply to an individual node, but also to all of its descendants. Since a node groups children, grandchildren and other descendants, a branch is called domain in AMS.
To see how rules apply to a domain, consider Figure 1.1
again. Suppose we set the access rights for the domain 'Elicited' to
something like 'readable by everybody'. This means that all the resources in the domain of
the node 'Elicited' are 'readable by everybody': i.e. the (only one in this case)
resources present in this domain - book1.wav - can be accessed by
everybody. Another example concerns the domain 'Spontaneous'. Suppose we want only some,
specific user to be able to access this domain: what we have to do is to set the rule
'readable by user X'. In this way, the resources conv1.txt,
conv2.txt and game_a.mpg will be readable
only by user X.
Nodes like 'Book', 'Telephone' and 'Game' in Figure 1.1 are called session nodes. They group all resources that are part of a meaningful unit of analysis. Nodes like 'Corpus', 'Elicited' and 'Spontaneous' are called corpus nodes. They group session nodes or other corpus nodes, giving the archive its tree-like structure.
Resources is a common name for all kinds of files that can be associated to session nodes. The resources are the very content of the corpus. Resources can be of the following types (with their respective formats):
Images, e.g. JPEG
Video files, e.g. MPEG
Audio files, e.g. WAV
Annotations/Text, e.g. EAF
Info files (all kind of files), e.g. PDF