One of the main advantages of using a hierarchical structured tiers is the possibility to split the content of an annotation unit on a parent tier automatically into smaller parts on another tier. This can be a child tier, but also an independent tier, outside of a hierarchy. E.g. the words on an utterance tier could be split into separate words. This is called tokenizing in ELAN. These steps will guide you through this process:
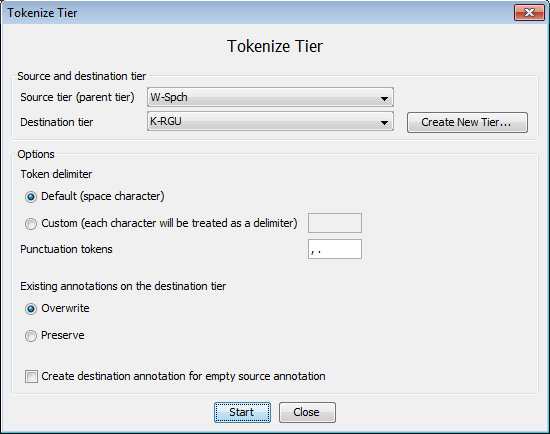
Go to
Select a Source (= parent) and Destination tier
Optionally create a new destination tier by selecting
Select a delimiter. The default is a space, but other choices are possible (e.g. “-” for morpheme breaks).
If you would like punctuation symbols tokenized as well, please specify them in the field next to 'Punctuation tokens'.
If the destination tier already contains annotation units, choose between overwriting or preserving them. If its still empty you can ignore this option.
Select if you want to create for every source annotation a destination annotation, even if its empty.
Click on Start, the tokenization will begin:
When it is finished, you will see that every annotation unit from the source tier has been tokenized on the destination tier:

All tokens (words in this example) on the destination tier have the same size (i.e. duration), even when tokenizing to a tier from the type time subdivision. You can adjust their length, as described in Section 2.8.7.
For symbolic associations, there is no need to use the tokenizer. Instead, go to the grid viewer and make sure the checkbox next to the dropdown menu is selected. Now you can fill in the annotations of the symbolic associations in their column of the grid. See also Section 1.5.7. If you want to copy or filter the contents from 1 tier to another symbolic associated tier, have a look at Section 2.13.
Tabs and newline characters are always treated as delimiters.