There are several different working modes, some of which are designed with a specific task in mind. The default mode is the Annotation Mode, a generic mode in which almost all functions are available. Most functions discussed in this document so far are shown in the Annotation Mode. Switching between modes can be done via the Options menu. The other modes are:
Synchronization mode:
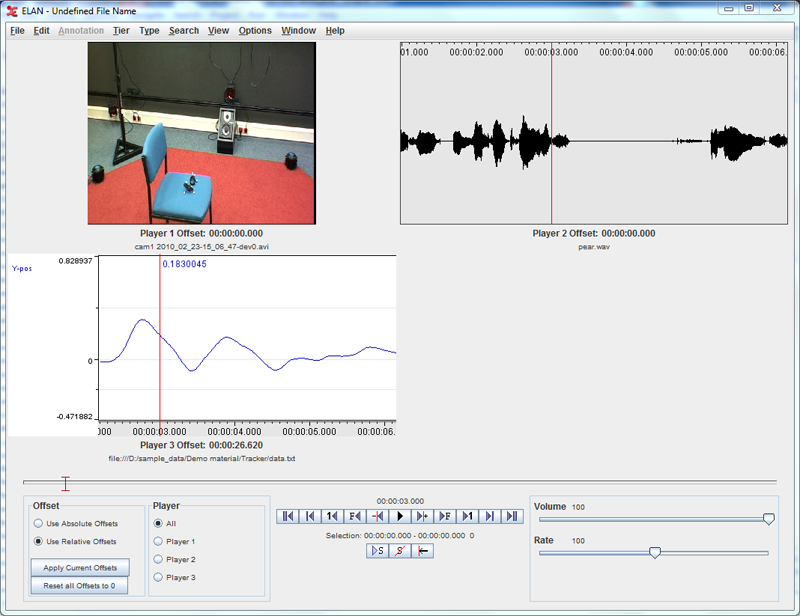
The Synchronization Mode allows the user to synchronize media files (video, audio, time series) of which the recording didn't’t start exactly at the same time. By setting an offset for some of the files in this mode, the media files will be played in sync in ELAN. The media files will not be clipped, this synchronization has only consequences while working with them in ELAN.
Transcription mode:
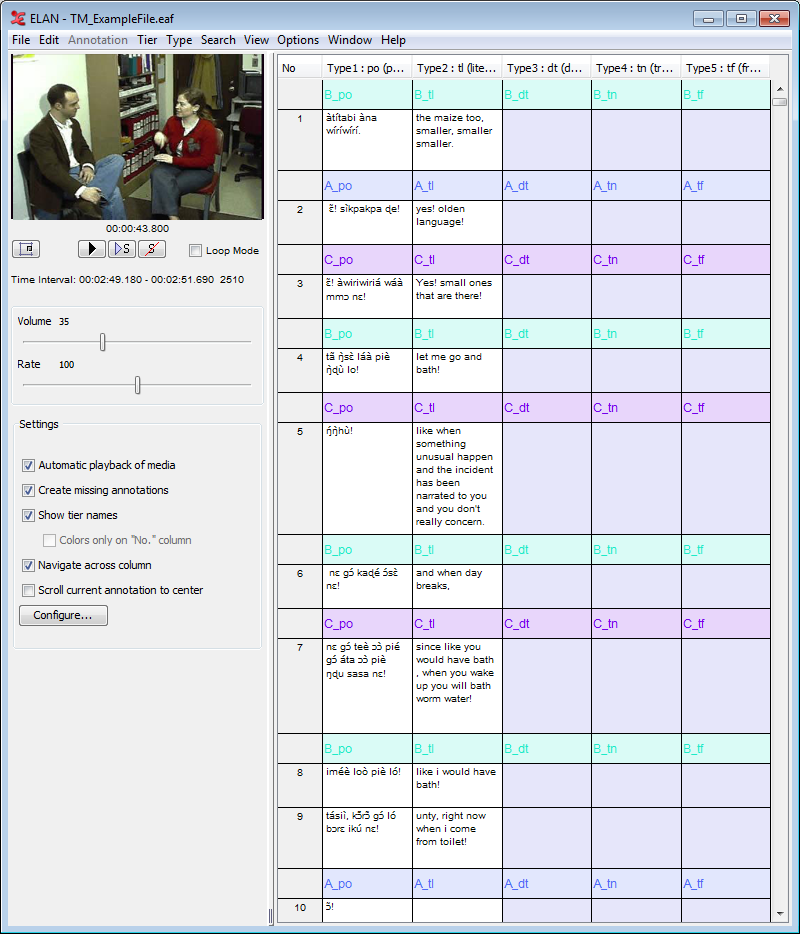
The Transcription Mode is optimized for typing text into existing annotations. Annotations are presented in a spreadsheet-like, tabular layout in which navigation (from one cell to another) is entirely keyboard driven. When a cell (i.e. annotation) is activated the corresponding segment of the media starts playing. The selection of the tiers that the user wants to be visible in the table is based on the type of the tiers; tiers of the same type are shown in the same column. E.g. the first column can contain all tiers of type “orthography“, the second column all tiers of type “translation” etc.
Segmentation mode:
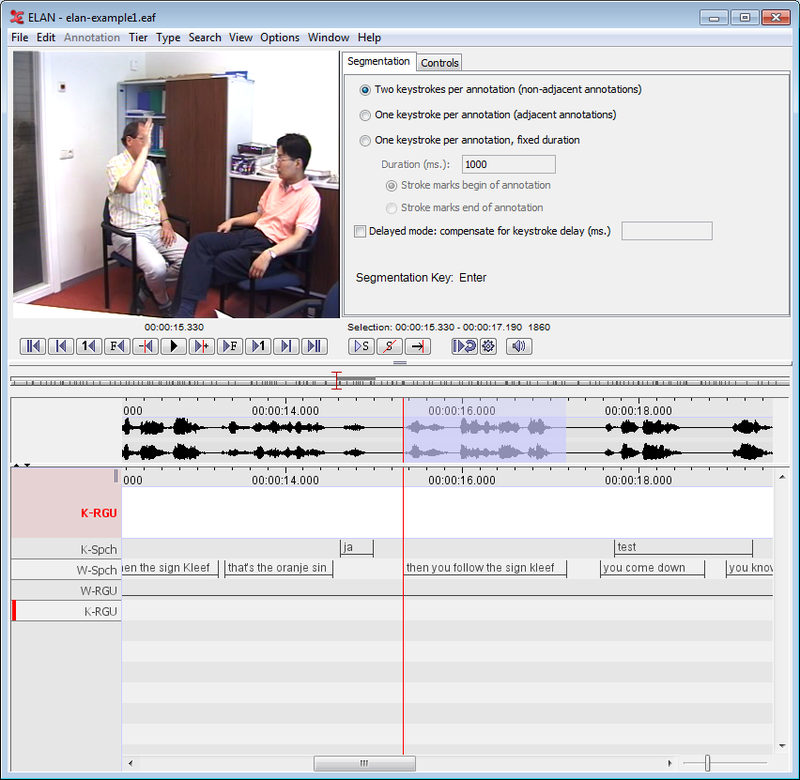
The Segmentation Mode is designed for rapid and easy creation of empty annotations while the media is playing. Marking the begin and end time of annotations is done using the keyboard. It is possible to change the boundaries of an annotation by dragging them with the mouse. Creating and changing the boundaries of an annotation in this mode does not require making a time selection first (like is the case in the Annotation Mode).
Interlinearization mode:
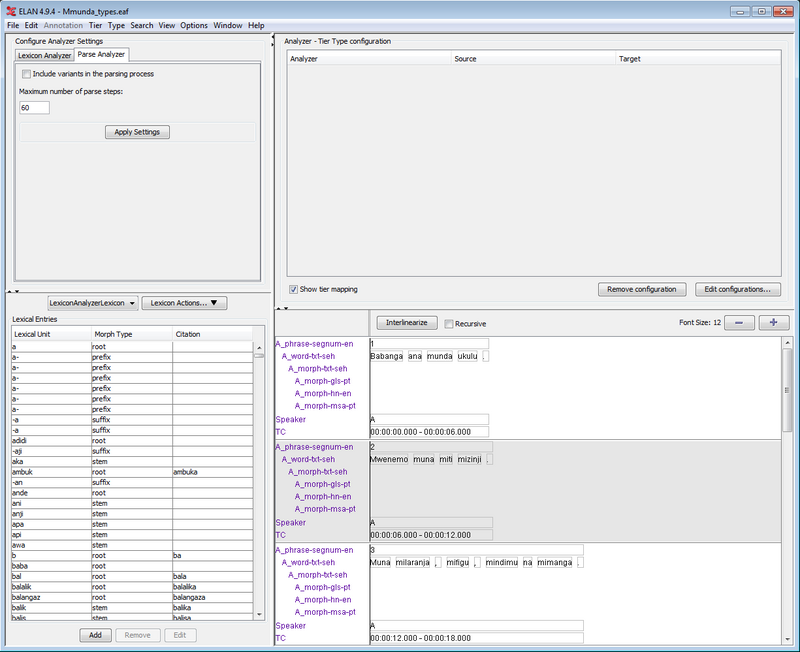
Interlinearization mode is a text oriented mode designed for parsing and glossing annotations to one or more lines of interlinearized text. This can be done manually or with the use of one or more so-called Analyzers. Analyzers are software modules that accept an annotation as input and produce suggestions for one or more annotations as output. Examples of the type of processing analyzers can perform are tokenization, morphological parsing and lookup of glosses. The segmentation and (typically) the transcription of speech events need to be done in one of the other modes before interlinearization can be added in this mode.
Part of the user interface of this mode is a Lexicon panel, the front end of a Lexicon Component module. It allows to create, import and edit a lexicon and its entries. Lexicons are stored separately from annotation data in a new data format. These are the lexicons that analyzers can get access to.