By default, the IMDI Browser gives access to all corpora that are stored at the Max Planck Institute for Psycholinguistics (MPI), Nijmegen, The Netherlands.
In addition – or alternatively – the Browser can display corpora created by you or by other archiving initiatives (see Section 2.1.1).
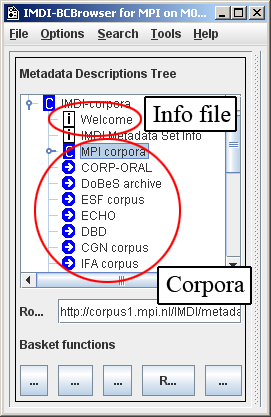
Currently, some of the corpora housed at the MPI are:
MPI corpora: Corpora collected by researchers affiliated with the Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands.
DoBeS archive: Corpora collected by researchers affiliated with the DoBeS (Dokumentation Bedrohter Sprachen) project funded by the Volkswagen foundation.
ESF corpus: European Science Foundation Second Language Acquisition Database.
CGN: Corpus Gesproken Nederlands.[2]
IFA corpus: Corpora collected by researchers affiliated with the Instituut voor Fonetische Wetenschappen (Institute of Phonetic Sciences), Amsterdam, The Netherlands.
![[Note]](images/note.png) | Note |
|---|---|
Depending on the version of the IMDI Browser, it may not always be possible to access all corpora. |
Each corpus contains further subcorpora collected by individual researchers or project teams. The internal structure of each subcorpus varies according to the purposes and needs of the project. You can access information about their content and structure through the info files displayed in the IMDI Browser (see Section 2.3.4.3).
Each corpus contains metadata, media, annotation and info files (see Section 2.3.4). These files can be accessed through the following two mechanisms (but please note that data files may not always be accessible to the general public; see Section 1.2):
By navigating through the hierarchical tree structure (see Section 2.3.1).
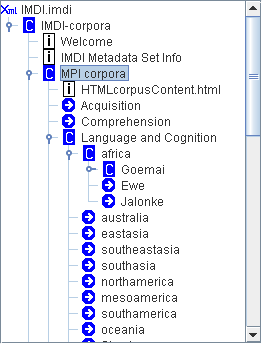
Each corpus is organized hierarchically in the form of tree structures (see Figure 1.2).
Tree structures consist of nodes that group files together on the basis of, e.g., the geographical region, the discourse genre, the sex or age of the speaker, the dialect of the speaker, the target/source language etc.
All nodes are displayed in the IMDI Browser. Double-click on a node to access the next level in the hierarchy.
At the lowest level of the hierarchy, the actual metadata, media, annotation and info files are displayed.
Note The tree structure does not display the physical location of files. This means that the same file can easily be displayed in different parts of the corpus, e.g., the same file may be displayed under the nodes ‘folktale’, ‘male speaker’, and ‘age-group 20 to 30 years’.
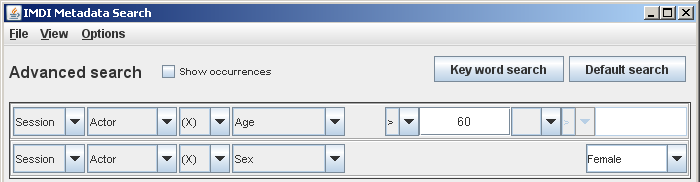
By searching the metadata files (see Chapter 3).
All resources or data files are accompanied by metadata files, i.e., files that give information about the data. These metadata files are searchable. For example, as illustrated below, you could search for all texts by female speakers above 60 years of age. The IMDI Browser displays the search results and allows you direct access to the corresponding data files.
[2] If you access the Corpus Gesproken Nederlands via the IMDI Browser, content searches are not possible. To conduct content searches in the CGN corpus, you need the corresponding CDs (see the separate manual “Corpus Gesproken Nederlands (COREX)” for details).