Projects at the Language Development department
Research projects at the Language Development Department are organised around three themes; Language over Development, Language across the World, and Language in the Brain.
Curious to find out what we are working on at the moment? You can find an overview of our current projects below.
- Language over Development
-
The Language 0-5 Project

The Language 0-5 Project, headed by Caroline Rowland, director of the Language Development Department, explores how children’s developing brain supports language learning and why some children develop language more quickly than others.
The Language 0-5 Project follows 80 English-learning children from 6 months to 5 years of age to build a comprehensive picture of language development from the very beginning through to school readiness. We are collecting a detailed longitudinal corpus of naturalistic, experimental, questionnaire and standardised measures of cognitive, socio-cognitive and linguistic development. This will enable us to develop explanations of the way in which children’s language-learning mechanisms interact with changes in their knowledge and processing abilities over the course of development. It will also allow us to determine how a child’s family circumstances affect language development, and deliver practical, evidence-based advice about the determinants of poor language growth.
The Language 0-5 Project is an initiative of the ESRC International Centre of Language and Communicative Development.
How does children’s language knowledge change over development?

Humans differ from each other in countless ways, with variability being apparent in many aspects of life, from the atomic to the social level. Children thus differ remarkably in how they acquire language, and yet, after years of learning, they manage to arrive at the same level of adult-like communication. Eleni Zimianiti, Seamus Donnelly, Rogier Kievit, and Caroline Rowland are studying individual differences in first language acquisition in Dutch. Using the acquisition of the Past Tense as a test bed case, they are exploring the between-verb characteristics that influence acquisition as well as within-individual differences across time. The goal of this project is to better understand how language and children’s individual differences are at play in language acquisition, and how children’s knowledge changes over development, as they learn to master their language.
How do children learn to use language creatively?
Children's utterances get more complex as they get older. In this project, we investigate how children go from producing one- and two-word utterances to comprehending and producing sentences with complex hierarchical structure. As children's language comprehension and planning improves, they start to harness the generative power of language. This means that they start to understand and create sentences they have not heard before. Children do this by extending words to novel contexts and by combining structures in a novel manner. A side effect of this emerging creativity is that they make very interesting errors. They over-extend words (e.g., using scissors to refer to all metal objects) and overgeneralize structures (e.g., she giggled me). All of this is part of an impressive learning process that results in the ability to use language productively. What are the learning mechanisms that support this learning? How do children learn from their input? How do they learn from their predictions, productions, and errors? And finally, how do children build hierarchical representations that help organise sequences of words? In this project, Zara Harmon uses corpus studies, experiments, and computational modelling to address these questions.
- Language across the World
-
The development of universal quantifiers
Quantifiers, like ‘all’ and ‘every’, are pivotal for everyday communication, because they allow us to efficiently speak about different numbers of objects. However, quantifier words are notoriously difficult to learn: Children make well-attested errors in the interpretation of words like ‘all’ up until late in language development. The challenge posed by these words is that they have a very abstract meaning. A word like ‘all’ does not refer to anything out there in our surrounding world, but describes abstract semantic properties of sets of things.
In this project, Mieke Slim examines how children learn universal quantifiers in a range of languages. Her main focus is on the development of universal quantifiers (words that quantify over a full set, like ‘all’, ‘every’, and ‘each’). These words are particularly interesting because many languages have multiple universal quantifiers that all slightly differ in meaning. In English, for example, ‘each’ means something slightly different than ‘all’. Moreover, languages differ in which properties of universal quantifiers are lexicalised. In English, for example, there is a small meaning difference between ‘each’ and ‘every’. In Dutch, however, both the meaning of ‘each’ and that of ‘every’ can be expressed with the same quantifier (‘elke’ or ‘iedere’). How do children, across languages, learn the similarities and differences between universal quantifiers? We use a range of methods to answer this question, such as corpus analysis of child-directed speech and behavioural experiments.How do children acquire and process verb-initial sentences?
Most of our knowledge on language acquisition comes from studies on English and other Indo-European languages. However, there is a vast diversity of languages and language features in the world, and if we want to fully understand how children acquire and process language, we have to sample beyond Indo-European languages. For example, we know little about verb-initial languages (e.g., imagine saying sentences like “pushing the cow the pig”). In order to understand how children acquire and process such sentences (and how they differ from other languages), Rowena Garcia and Evan Kidd are studying the acquisition of Tagalog, a verb-initial language from the Philippines. They use both corpus analysis (i.e., examining video recordings of interactions and utterances produced by Tagalog-speaking child-guardian pairs) and behavioural methods like eye-tracking (involves selecting the picture that corresponds to the sentence that they heard) and structural priming (involves describing action pictures); in order to understand the input that children hear, and their understanding and production of verb-initial sentences.
Cross-linguistic influence in Irish-English bilingual language development.
When bilingual children use one of their languages, they sometimes express themselves in a way that is not quite usual in that language, but that is perfectly normal in the other language they know. A Dutch-English bilingual child might say, "I find this not nice", which is a normal way to express yourself in Dutch: "Ik vind dit niet leuk". But it sounds a bit odd to English speakers, who might rather say, "I don't like this". This phenomenon is called Cross-Linguistic Influence, CLI for short: one language influences the other. And while we know that CLI is a common phenomenon in how bilingual children (and adults) use their languages, we do not understand it well, yet. Previous research has shown that language dominance, surface overlap of morphosyntactic structures, and age, might play a role in CLI, but findings have been inconsistent. To better understand why and when CLI happens, Clara Kunst, Evan Kidd, and Sharon Unsworth are using a cross-language priming and a visual world eye-tracking paradigm to investigate CLI during language production and comprehension in Irish-English bilingual children. They investigate how language dominance affects bidirectional CLI at the level of morphosyntax and if and how English-to-Irish CLI might be affecting adult language use in Irish. The goal of this project is to improve our understanding of CLI and by doing so, to better understand how bilingual children learn two languages at the same time.
Does looking behaviour play a different role in language acquisition depending on language modality?

Looking behaviours are an important aspect of communication. Parents and children use gaze to link the information that is shared through language to the environment around them. Research has shown that children make use of the information they receive through gaze and that it helps them learn new words and signs. Jennifer Sander and Yayun Zhang are investigating how this relationship between language and shared gaze between caregiver and child is influenced by the modality of the language parents and children use; sign or spoken language. In an innovative mobile lab we are visiting signing and speaking families all over the Netherlands to investigate their looking behaviours using head-mounted eye tracking. We hope to gain a better understanding of the role gaze plays in language acquisition processes in general, and in spoken Dutch and Sign Language of the Netherlands in particular.
Who did what to whom in German and Russian?
Understanding who-is-doing-what-to-whom requires assigning thematic roles of agent (e.g. ‘the dog’ in ‘the dog bit the man’) and patient (‘the man’) to the referents in a transitive event. The crucial question is what information (cues) children rely on when assigning thematic roles. Languages use different means to signal the roles of the agent and a patient. German and Russian have flexible word order and use case-marking to mark the roles of the agent and the patient. However, past research suggests that children acquiring these languages follow different developmental trajectories. While German-speaking preschoolers tend to rely on word order, not using case marking to assign thematic roles until the age of 7, Russian-speaking preschoolers already use case-marking to assign the roles of the agent and patient. This difference aross the two langauges is intriguing since both languages use case-marking to signal thematic roles.
In this project Yevheniy Skyra, Rowena Garcia and Evan Kidd investigate how the grammatical properties of the language children acquire together with the distributions properties of the language input children receive influence development of thematic roles assignment. To answer these questions we use corpus analysis of child- and child-directed speech as well as online (eye-tracking) and offline (sentence picture matching task) methods.
- Language in the Brain
-
The baby brain: From early neural development to later language acquisition

It is now clear that changes that take place in the brain in the first year of life lay the foundations for later cognitive development, including language acquisition. Some evidence suggests that individual brain development in the first year of life might predict individual differences in later language acquisition. However, this literature is not large, participant numbers are frequently low and results are inconsistent. Importantly, studies are usually not longitudinal, which means that we lack the knowledge of how (individual) changes across the first year of life affect later language. Additionally, very little work (if any) relates the genetic predisposition and the environmental input to see how the combination and interaction of the two influences early brain development and later language acquisition. This means that we still don’t know why there are individual differences in brain development that affect later language. Led by Sergio Miguel Pereira Soares, the early precursors project goal is to longitudinally investigate early life neurobiological correlates and their predictive validity for later language and cognitive development. Furthermore, we are going to use complex statistical analyses to determine the influence that environmental and genetic measures have on the brain and language.
Bilingualism in the developing brain
Having more than one language in the brain is not uncommon in modern societies. In fact, over 50% of the global population is bilingual, indicating that a significant portion of younger generations is growing up in bilingual or multilingual environments. Therefore, it's crucial to have a clear understanding of how developing brains adapt to bilingual experiences.
In this project, Chih Yeh and Sergio Miguel Pereira Soares are investigating the impact of bilingualism on neurobiological changes in the developing brain, using electroencephalography (EEG) and functional near-infrared spectroscopy (fNIRS) methods. Our focus is on understanding the underlying neural mechanisms of bilingual children's lexical and morphological semantic development. Additionally, we are examining whether factors related to bilingual experience, such as age of exposure, the amount of exposure, and proficiency in both languages, contribute to individual differences during development.
Multimodal language processing in the infant brain
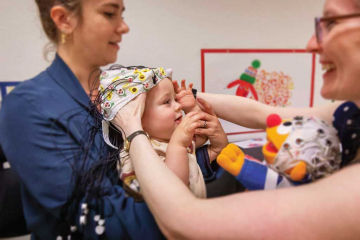
Babies and children learn language through interacting with their caregivers (e.g. when playing, reading books, holding conversations over dinner etc.). In these interactions, social cues such as eye gaze are thought to play an important role: when we talk with babies, our eyes provide a lot of information about what we are talking about. Likewise, when they are communicating with their caregivers, babies not only hear speech, but can also see the lip and mouth movements of the caregiver. These mouth movements, also called “visual speech cues” are thought to help babies in processing and learning from speech.
Melis Çetinçelik and Tineke Snijders are investigating the effects of these social and visual speech cues on babies' speech processing and learning, using a method called ““electroencephalography” (EEG). This project aims to investigate whether babies’ brains respond differently to speech when the speaker is looking at them, compared to when the speaker is looking elsewhere; and whether they process speech better when they can see the mouth movements of the speaker, compared to when these cues are covered (such as when the speaker is wearing a face mask). Together, this project aims to understand the role of different visual multimodal cues on early speech processing and language acquisition.How children use their daily experiences to learn word meanings
Young children are skilled word learners. However, word learning is not trivial for the young child because, in principle, there are an unlimited number of referents embedded in the learning moment. How do infants know which word label maps onto which referent? To investigate this research question, Yayun Zhang is conducting a series of studies focussed on verb learning. In the word learning literature, there is consensus that verb-meaning mappings are harder to learn than noun-object mappings. In verb learning, identifying a target referent is necessary but not sufficient to learn the meaning of a verb, which usually describes a relation within an event. Because an event can be conceptualised in terms of a multitude of relations, it is difficult to infer the meaning of a verb when there are many possible generalisations that one can make from a single event.
Attempts to understand the unique challenges of verb learning have generally focused on the linguistic structures in which verbs occur (i.e., syntactic bootstrapping). Fewer studies have focused on verb concepts themselves and how they are visually represented in the child’s first-person visual environment. This study aims at investigating how children gradually build and refine verb meaning space using input from their everyday experiences and how their verb knowledge changes through early childhood.
How does shared book reading support language development?
A plethora of studies indicates a positive connection between shared reading books and various aspects of language development. It has been found that extra-textual talk generated during shared book reading contains a higher level of structurally rich linguistic construction than child directed speech generated in other everyday contexts such as mealtime, dressing, and toy play. However, it is unclear how young children process the diverse linguistic input provided during shared book reading in real time and how additional extralinguistic input, such as gestures, work together with linguistic input in this learning process.
Yayun Zhang is leading a naturalistic dual head-mounted eye tracking study to investigate how toddlers learn the correct word-object mappings by attending to the right object at the moment of parent naming in shared book reading. By analysing parent and child’s real-time speech, attention and gestures, this study tells us how parents and toddlers coordinate various information sources during shared book reading to support language learning. - Innovations Team projects
-
How speaking and signing children learn words and signs across the Netherlands
Like any other skill, children learn language at different speeds. The speed of acquisition depends on many different factors, such as the environmental input children receive, their motoric development and the maturation of the neural pathways of the brain. And to assess the effect of different factors on a child’s language abilities, we need to have good measures to assess these language abilities.
The MacArthur-Bates Communicative Development Inventories (CDIs) are reliable and accurate measures of children's language comprehension and production; parent-report checklists of the words and signs, gestures, and sentences that a young child may know and/or produce. But each CDI needs to be tailored to each specific language, to take account of differences across languages and cultures.
Marieke van den Akker and Caroline Rowland, together with Elma Blom, Liesbeth Schlichting and Inge Zink are working on a new adaptation of the Flemish-Dutch CDI, adapting it to the specific language and cultural context of the Netherlands. In addition, Jennifer Sander and Caroline Rowland, together with Anne Baker and Beppie van den Bogaerde are developing the first video-based CDI for Sign Language of the Netherlands, which accounts for language modality and specific aspects of Deaf culture.
Moving CDI data collection online
Together with the Stanford Language and Cognition lab, we have built Web-CDI, a web-based tool which allows researchers to collect CDI data online, and which contains functionality to collect and manage longitudinal data, share links to test administrations, and download vocabulary scores. All of the vocabulary data collected in Web-CDI are stored in a standard MySQL relational database, managed using Django and Python and hosted either by Amazon Web Services or by a European Union (GDPR) compliant server. Individual researchers can download data from their studies through the researcher interface, and Web-CDI administrators have access to the entire aggregate set of data from all studies run with Web-CDI. More information, you can find here.
Building better annotation tools
To find out how children use the information in their environment to learn a language, we need to analyse what this environment is; what do they hear, see, touch, and smell in their daily lives? However, we lack the tools needed to record, transcribe, annotate, and analyse these experiences on a large scale. Researchers at the Language Development Department are working with The Language Archive, and teams across the world, to develop semi-automated methods for analysing audio-video records of child language experiences and environments.
For example, together with the Cognitive Machine Learning team in Paris, and The Language Archive here at MPI, we are developing a cloud-based platform for the storage, annotation, and semi-automatic analysis of everyday language data. The platform will a) enable researchers to acquire, store, annotate, analyze and share their audio-video recordings while maintaining data confidentiality, b) help researchers plan and organise annotation campaigns and c) allow researchers to use machine learning/AI algorithms for pre-annotation tasks (e.g. pre-segment the annotation file into speech/non-speech events) and for analysis. The goal of the project is to facilitate the production of reliable, time-saving tools that can be used by scientists to analyse and compare children’s language environments around the world.
The MEDAL consortium
Methodological Excellence in Data-Driven Approaches to Linguistics (MEDAL) is an European Commission-funded collaboration between MPI for Psycholinguistics and Radboud University here in the Netherlands, University of Birmingham in the UK and University of Tartu in Estonia, and is designed to build expertise in data-driven linguistic methodology consortium by supporting early-career researchers with mobility grants, developing collaborative research projects between the partner institutes and providing training in linguistic research methods and soft skills. You can find out more here.
Reproduction and replication: Open Science at the Language Development Department
The ultimate aim of all research is to gain new insights that are relevant for everyone. An important step in that process is being transparent and conscientious about as much of our work as possible; in other words, making science open. The resulting transparency and availability of research output ensures that results can be reproduced (so we can check conclusions) and replicated (so we can carry out new studies on the same question). The Max Planck Institute for Psycholinguistics has long been at the forefront of open science, with initiatives increasing access that range from shared materials and data at The Language Archive, to free tools developed by the Innovations team, and freely accessible publications thanks to the library staff.
Share this page