- Language Processing and Learning Cluster
-
Members:
Candice Frances (Cluster leader-Postdoctoral researcher)
Antje Meyer
Constantijn van der Burght (Postdoctoral researcher)
Caitlin Decuyper (PhD student)
Cecilia Husta (PhD student)
Christina Papoutsi (PhD student)
Franziska Schulz (PhD student)
Morgane Peirolo (PhD student)
Veerle Wilms (PhD student)
Yuxi Zhou (PhD student)Group description:
Although we use language every day, there are many unanswered questions about how we achieve this feat. Our diverse team of researchers investigates a broad spectrum of topics, ranging from the temporal dynamics of prosody planning to the intricacies of lexical access and word selection. Through a combination of methodologies such as EEG analysis, experimental studies on speech production in background noise, and investigations into the impact of pitch accents on verbal memory and a combination of methods (EEG, eye-tracking, and behavioral), we strive to unravel the complexities of language processing in various contexts. Our area of study lies at the intersection of language production, comprehension, and cognitive mechanisms, aiming to deepen our understanding of how humans perceive, produce, and comprehend language.
Collaborators:
Stavroula Alexandropoulou
Eva Belke
Angela de Bruin
Marc Brysbaert
Matthew Crocker
Francesca Delogu
Clara Ekerdt
Stefan Frank
Lauren Hadley
Gesa Hartwigsen
Judith Holler
Iva Ivanova
Clara Martin
Vitoria Piai
Martin Pickering
Greg Scontras
Emiliano Zaccarella
- The Cultural Brain
-
The Cultural Brain research group, led by Falk Huettig, investigates how cultural inventions – such as written words, numbers, music, and belief systems – shape our mind and brain from the day we are born.
Our research is divided into three themes (the Literate Brain, the Predictive Brain, and the Multimodal Brain), each of which provides us with a unique window for exploring the culturally-shaped mind.
We use behavioural measures, functional and structural neuroimaging techniques, and computational modelling to help us answer the central question: To what extent does culture determine what it means to think as a human?
For more information about our research team and current projects, visit the Cultural Brain research group page.
- Individual Differences in Language Skills
-
Individual differences are ubiquitous in our daily lives, and language is no exception. While some people are essentially ‘walking dictionaries’ with versatile vocabularies, others rely on smaller, possibly more specialized sets of words. Similarly, individuals differ substantially in their speech rate: While some people are astonishingly fast speakers, others tend to ‘take their time’.
In this cluster, we investigate individual differences in speaking, listening, and reading. We ask how these language-related differences are influenced by variability in linguistic knowledge (such as vocabulary, grammar knowledge, and idiomatic expressions) or general cognitive skills (such as processing speed, working memory capacity and non-verbal reasoning). We also ask how basic processing skills (e.g., producing and comprehending words and sentences) affect speaking and listening in more complex settings, such as having a conversation.In collaborations with researchers from the Max Planck Institute for Psycholinguistics (Psychology of Language department together with the Neurobiology of Language Department and the Language and Genetics Department) and the Donders Institute for Brain Cognition and Behavior, we explore neurobiological and genetic bases of variability in language skills.
This cluster was born out of the past project Variability in language processing and language learning, led by Antje Meyer and James McQueen, which was funded by the Netherlands Science Organization as part of the Language in Interaction consortium.
How do we conduct our research?
Between 2017 and 2022, we developed and validated the Dutch Individual Differences in Language Skills (IDLaS-NL) test battery—a set of behavioral tests measuring linguistic knowledge, general cognitive skills, and linguistic processing skills. We applied the test battery to ~750 younger Dutch adults, aged between 18 and 30. All participants provided us with a saliva sample for genetic analyses. About 200 of these participants additionally underwent extensive magnetic resonance imaging (MRI) testing, where function and structure of their brains were assessed. Behavioral, neurobiological and genetic analyses are currently underway and will be published in due time.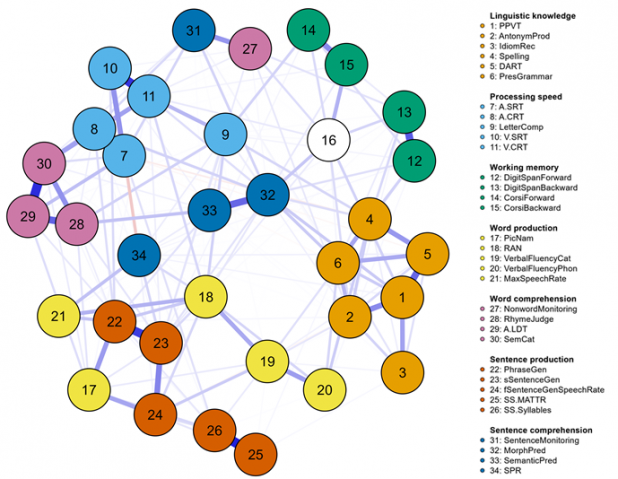
A web platform for running customized studies via the internet
The IDLaS-NL test battery is freely available for anyone interested (researchers, clinicians, teachers) in running studies on individual differences in language and general cognitive skills via the internet. We created a web platform with an intuitive graphical interface for users to make selections of the behavioral tests they wish to include in their own research, to divide these tests into different sessions and to determine their order. Moreover, for standardized administration the platform provides an app (an emulated browser) wherein the tests are run and results are provided as a CSV file via email.The IDLaS-NL platform can be accessed at www.mpi.nl/idlas-nl.

The German version of the battery, IDLaS-DE is also under development. After extensive piloting, the validation study is now live. A customizable battery will be released for these tasks soon. To participate or learn more, click here, or get in contact with Sandra Bethke.
Development has also begun on an English version of the battery, IDLaS-EN. The battery is in initial pilot stages, but there are plans to release a customizable interface with the first selection of tasks in summer 2024. To learn more, click here, or get in contact with Kyla McConnell
Members and collaborators
Sandra Bethke
Marius Braunsdorf
Else Eising
Simon Fisher
Candice Frances
Stephanie Forkel
Laura Giglio
Peter Hagoort
Florian Hintz
Milou Huijsmans
Rogier Kievit
Birgit Knudsen
Rogier Mars
Kyla McConnell (cluster coordinator)
James McQueen
Antje Meyer
Janay Monen
Franziska Schulz
Ingrid Szilagyi
Atsuko Takashima
Stan van der Burght - Prosody production and perception
-
When we speak, we produce variations in the intonation, rhythm, and loudness of our voice. These characteristics of speech (together called: prosody) play an important role during everyday communication. Prosody can highlight new or particularly relevant information in a sentence, it can influence the processing of grammatical structure, and it can communicate the speaker’s intention or emotional state. Listeners rapidly implement prosodic information into a sentence representation and speakers use prosody effortlessly to convey their intended meaning. Yet, fundamental questions surrounding prosody processing remain.
The researchers in this group aim to find answers to questions such as: How do conversation partners use and interpret prosody to convey what are particularly relevant parts of their message? How do speakers plan the proosidc characteristics of their sentence together with the specific words they produce? And how do speakers and listeners vary in prosody processing, both in the way they perceive prosodic cues and in the way they produce them? To answer these questions, behavioural and neuroimaging methods are used, in addition to the phonetic and phonological analysis of speech recordings.
Members and collaborators
Candice Frances
Antje Meyer
Morgane Peirolo
Stan van der Burght (chair)
Yuxi Zhou
Ruth Corps (University of Sheffield)
Elli Tourtouri (University of Osnabrück)
Joanne Chan (University of Groningen)
Helin Erdem (University of Amsterdam)
Giulia Li Calzi (University of Trento) - Research Tools
-
Test battery
Hintz et al. (in preparation). IDLaS-NL – A platform for running customized studies on individual differences in language skills via the internet.
Materials
Decuyper et al. (in preparation). Bank of Standardized Stimuli (BOSS): Dutch names for 1300 photographs.
Duñabeitia, J. A., Crepaldi, D., Meyer, A. S., New, B., Pliatsikas, C., Smolka, E., & Brysbaert, M. (2018). MultiPic: A standardized set of 750 drawings with norms for six European languages. Quarterly Journal of Experimental Psychology, 71(4), 808-816. doi:10.1080/17470218.2017.1310261.
De Groot, F., Koelewijn, T., Huettig, F., & Olivers, C. N. L. (2016). A stimulus set of words and pictures matched for visual and semantic similarity. Journal of Cognitive Psychology, 28(1), 1-15. doi:10.1080/20445911.2015.1101119.
Shao, Z., Roelofs, A., & Meyer, A. S. (2014). Predicting naming latencies for action pictures: Dutch norms. Behavior Research Methods, 46, 274-283. doi:10.3758/s13428-013-0358-6.
Shao, Z., & Stiegert, J. (2016). Predictors of photo naming: Dutch norms for 327 photos. Behavior Research Methods, 48(2), 577-584. doi:10.3758/s13428-015-0613-0.
Methods
Bosker, H. R. (2021). Using fuzzy string matching for automated assessment of listener transcripts in speech intelligibility studies. Behavior Research Methods, 53(5), 1945-1953. doi:10.3758/s13428-021-01542-4.
Corcoran, A. W., Alday, P. M., Schlesewsky, M., & Bornkessel-Schlesewsky, I. (2018). Toward a reliable, automated method of individual alpha frequency (IAF) quantification. Psychophysiology, 55(7): e13064. doi:10.1111/psyp.13064.
Rodd, J., Bosker, H. R., Ten Bosch, L., & Ernestus, M. (2019). Deriving the onset and offset times of planning units from acoustic and articulatory measurements. The Journal of the Acoustical Society of America, 145(2), EL161-EL167. doi:10.1121/1.5089456.
Schillingmann, L., Ernst, J., Keite, V., Wrede, B., Meyer, A. S., & Belke, E. (2018). AlignTool: The automatic temporal alignment of spoken utterances in German, Dutch, and British English for psycholinguistic purposes. Behavior Research Methods, 50(2), 466-489. doi:10.3758/s13428-017-1002-7.
Shao, Z., Janse, E., Visser, K., & Meyer, A. S. (2014). What do verbal fluency tasks measure? Predictors of verbal fluency performance in older adults. Frontiers in Psychology, 5: 772. doi:10.3389/fpsyg.2014.00772.
Shao, Z., & Meyer, A. S. (2018). Word priming and interference paradigms. In A. M. B. De Groot, & P. Hagoort (Eds.), Research methods in psycholinguistics and the neurobiology of language: A practical guide (pp. 111-129). Hoboken: Wiley.
Veenstra, A., Acheson, D. J., & Meyer, A. S. (2014). Keeping it simple: Studying grammatical encoding with lexically-reduced item sets. Frontiers in Psychology, 5: 783. doi:10.3389/fpsyg.2014.00783.
-
Past Projects
-
The Juggling Act Cluster: Speaking and Listening in Conversation
The Juggling Act Cluster has ended with Dr. Ruth Corps moving to The University of Sheffield.
The Representation and Computation of Structure (RepCom) group
The RepCom Cluster has ended with the initiation of the Max Planck Independent Research Group "Language and Computation in Neural Systems"
The TEMPoral Organisation of Speech (TEMPOS) group
The TEMPOS Cluster ended in 2022 with Dr. Hans Rutger Bosker moving to Radboud University, where he leads his Speech Perception in Audiovisual Communication (SPEAC) group.
Share this page